深度学习推荐系统 / 王喆编著. —北京:电子工业出版社,2020.3
ISBN 978-7-121-38464-6
第1章 互联网的增长引擎推荐系统#
1.1 为什么推荐系统是互联网的增长引擎#
1.1.1 推荐系统的作用和意义#
- 用户角度:推荐系统解决在“信息过载”的情况下,用户如何高效获得感兴趣信息的问题。从用户需求层面看,推荐系统是在用户需求并不明确的情况下过滤信息,因此,与搜索系统(用户会输入明确的“搜索词”)相比,推荐系统更多地利用用户的各类历史信息“猜测”其可能喜欢的内容。
- 公司角度:互联网企业的核心需求是“增长”,而推荐系统处在“增长引擎” 的核心位置。推荐系统解决产品能够最大限度地吸引用户、留存用户、增加用户黏性、提高用户转化率的问题,从而达到公司商业目标连续增长。不同业务模式的公司定义的具体推荐系统优化目标不同,例如,视频类公司更注重用户观看时长,电商类公司更注重用户的购买转化率(Conversion Rate,CVR),新闻类公司更注重用户的点击率,等等。
1.1.2 推荐系统与YouTube的观看时长增长#
推荐系统的“终极”优化目标应包括两个维度:用户体验的优化、满足公司的商业利益。健康的商业模式这两个维度应该统一。
YouTube 是全球最大的 UGC(User Generated Content,用户生成内容)视频分享平台,其优化用户体验结果的最直接体现就是用户观看时长的增加。YouTube 作为一家以广告为主要收入来源的公司,其商业利益建立在用户观看时长增长之上,因为总用户观看时长与广告的总曝光机会成正比,只有不断增加广告的曝光量,才能实现公司利润的持续增长。因此,YouTube 的用户体验和公司利益在“观看时长”这一点上达成了一致。
正因如此,YouTube 推荐系统的主要优化目标就是观看时长,而非传统推荐系统看重的“点击率”。其大致推荐流程是:构建深度学习模型预测用户观看某候选视频的时长,再按照预测时长进行候选视频的排序,形成最终推荐列表。
1.2 推荐系统的架构#
- “物品信息”:在商品推荐中指的是“商品信息”,在视频推荐中指的是“视频信息”,在新闻推荐中指的是“新闻信息”;
- “用户信息”:为了更可靠地推测出“人”的兴趣点,推荐系统希望利用大量与“人”相关的信息,包括历史行为、人口属性、关系网络等;
- “场景信息”或“上下文信息”:在推荐场景中,用户的最终选择会受时间、地点、用户的状态等环境信息的影响。
1.2.1 推荐系统的逻辑框架#
在获知“用户信息”、“物品信息”、“场景信息”的基础上,推荐系统要处理的问题可定义为:对用户 U(user),在特定场景 C(context)下,针对海量的“物品”信息,构建函数 f(U, I, C),预测用户对特定候选物品(item)的喜好程度,再根据喜好程度对所有候选物品排序,生成推荐列表的问题。
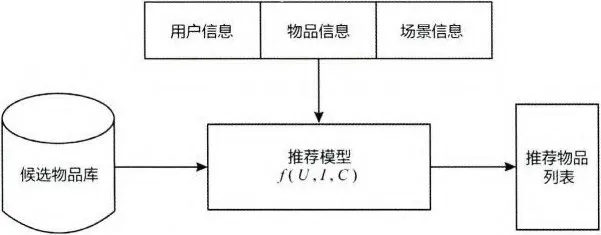
1.2.2 推荐系统的技术架构#
在图1-3 的基础上,工程师需要着重解决的问题有两类。
(1)数据和信息相关的问题,即“用户信息”“物品信息”“场景信息”分别是什么?如何存储、更新和处理?
(2)推荐系统算法和模型相关的问题,即推荐模型如何训练、如何预测、如何达成更好的推荐效果?
可以将这两类问题分为两个部分:“数据和信息”部分逐渐发展为推荐系统中融合了数据离线批处理、实时流处理的数据流框架;“算法和模型”部分则进一步细化为推荐系统中集训练(training)、评估(evaluation)、部署(deployment)、线上推断(online inference)为一体的模型框架。具体地讲,推荐系统的技术架构示意图如图1-4 所示。
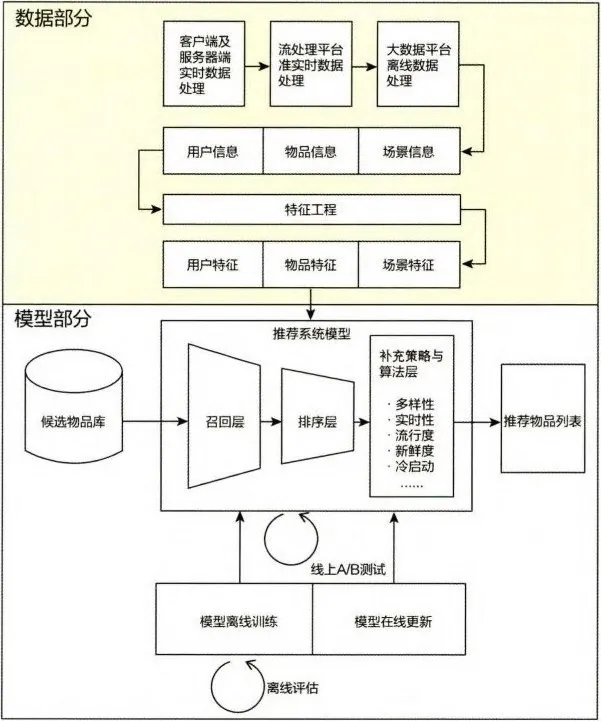
1.2.3 推荐系统的数据部分#
负责数据收集与处理的三种平台在实时性由强到弱递减的同时,三种平台的海量数据处理能力则由弱到强。
在得到原始的数据信息后,推荐系统的数据处理系统会将原始数据进一步加工,加工后的数据出口有三:
(1)生成推荐模型所需的样本数据,用于算法模型的训练和评估;
(2)生成推荐模型服务(model serving)所需的“特征”,用于推荐系统的线上推断;
(3)生成系统监控、商业智能(Business Intelligence,BI)系统所需的统计型数据。
1.2.4 推荐系统的模型部分#
“召回层”一般利用高效的召回规则、算法或简单的模型,快速从海量的候选集中召回用户可能感兴趣的物品。
“排序层”利用排序模型对初筛的候选集精排序。
“补充策略与算法层”,也被称为“再排序层”,在将推荐列表返回用户之前,为兼顾结果的“多样性”“流行度”“新鲜度”等指标,结合补充策略和算法调整推荐列表。
从推荐模型接收到所有候选物品集到最后产生推荐列表前,需要通过模型训练(model training)确定模型结构、结构中不同参数权重的具体数值,以及模型相关算法和策略中的参数取值。模型的训练方法又可以根据模型训练环境的不同,分为“离线训练”和“在线更新”两部分,其中:离线训练的特点是可以利用全量样本和特征,使模型逼近全局最优点;在线更新则可以准实时地“消化”新的数据样本,更快地反映新的数据变化趋势,满足模型实时性的需求。
除此之外,为了评估推荐模型的效果,方便模型的迭代优化,推荐系统的模型部分提供了“离线评估”和“线上 A/B 测试”等评估模块,用得出的线下和线上评估指标,指导下一步的模型迭代优化。
模型部分,特别是“排序层”模型是推荐系统产生效果的重点。
1.2.5 深度学习对推荐系统的革命性贡献#
与传统的推荐模型相比,深度学习模型对数据模式的拟合能力和对特征组合的挖掘能力更强。深度学习模型结构的灵活性,使其能够根据不同推荐场景调整模型,使之与特定业务数据“完美”契合。
深度学习对海量训练数据及数据实时性的要求,也对推荐系统的数据流部分提出挑战。
第2章 前深度学习时代——推荐系统的进化之路#
2.1 传统推荐模型的演化关系图#
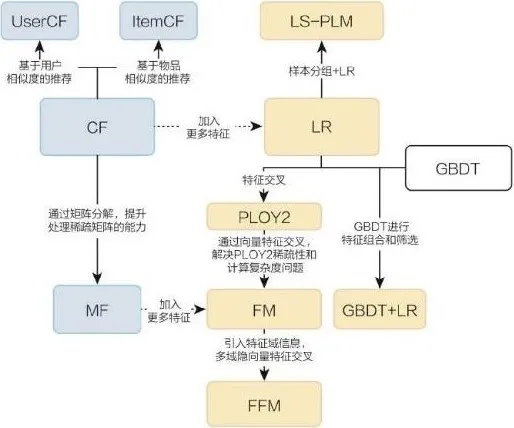
蓝色部分:协同过滤算法族
2.2 协同过滤——经典的推荐算法#
2.2.1 什么是协同过滤#
“协同过滤”就是协同大家的反馈、评价和意见过滤海量的信息,从中筛选出目标用户可能感兴趣的信息。这里用一个商品推荐的例子来说明协同过滤的推荐过程(如图2-2所示)。
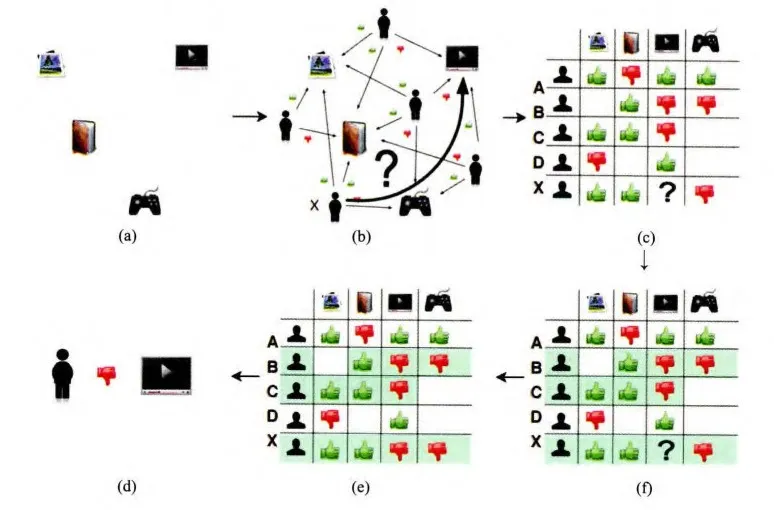
图 2-2 描述了电商网站场景下的协同过滤推荐过程,其推荐过程按照图 2-2(a)~(f)的顺序共分为 6 步。
(1)电商网站的商品库里一共有 4 件商品:游戏机、某小说、某杂志和某品牌电视机。
(2)用户 X 访问该电商网站,电商网站的推荐系统需要决定是否推荐电视机给用户 X。换言之,推荐系统需要预测用户 X 是否喜欢该品牌的电视机。为了进行这项预测,可以利用的数据有用户 X 对其他商品的历史评价数据,以及其他用户对这些商品的历史评价数据。图 2-2(b)中用绿色“点赞”标志表示用户对商品的好评,用红色“踩”的标志表示差评。可以看到,用户、商品和评价记录构成了带有标识的有向图。
(3)为便于计算,将有向图转换成矩阵的形式(被称为“共现矩阵”),用户作为矩阵行坐标,商品作为列坐标,将“点赞”和“踩”的用户行为数据转换为矩阵中相应的元素值。这里将“点赞”的值设为 1,将“踩”的值设为 -1,“没有数据”置为 0(如果用户对商品有具体的评分,那么共现矩阵中的元素值可以取具体的评分值,没有数据时的默认评分也可以取评分的均值)。
(4)生成共现矩阵之后,推荐问题就转换成了预测矩阵中问号元素(图 2-2(d)所示)的值的问题。既然是“协同”过滤,用户理应考虑与自己兴趣相似的用户的意见。因此,预测的第一步就是找到与用户 X 兴趣最相似的 n(Top n 用户,这里的 n 是一个超参数)个用户,然后综合相似用户对“电视机”的评价,得出用户 X 对“电视机”评价的预测。(超参数是在机器学习算法中需要手动设置的参数,它们不是通过训练数据学习得到的,而是在算法运行之前设置的。超参数的选择通常基于经验、试验和交叉验证等方法确定)
(5)从共现矩阵中可知,用户 B 和用户 C 由于跟用户 X 的行向量近似,被选为 Top n(这里假设 n 取 2)相似用户,由图 2-2(e)可知,用户 B 和用户 C 对“电视机”的评价都是负面的。
(6)相似用户对“电视机”的评价是负面的,因此可预测用户 X 对“电视机”的评价也是负面的。在实际的推荐过程中,推荐系统不会向用户 X 推荐“电视机”这一物品。
以上描述了协同过滤的算法流程,其中关于“用户相似度计算”及“最终结果的排序”过程是不严谨的,下面重点描述这两步的形式化定义。
2.2.2 用户相似度计算#
在协同过滤的过程中,用户相似度的计算是算法中最关键的一步。
共现矩阵中的行向量代表相应用户的用户向量。那么,计算用户i和用户j的相似度问题,就是计算用户向量i和用户向量j之间的相似度,两个向量之间常用的相似度计算方法有如下几种。
(1)余弦相似度,如(式 2-1)所示。余弦相似度(Cosine Similarity)衡量了用户向量 i 和用户向量 j 之间的向量夹角大小。显然,夹角越小,证明余弦相似度越大,两个用户越相似。
(2)皮尔逊相关系数,如(式 2-2)所示。相比余弦相似度,皮尔逊相关系数通过使用用户平均分对各独立评分进行修正,减小了用户评分偏置的影响。
其中, 代表用户 对物品 的评分。 代表用户 对所有物品的平均评分, 代表所有物品的集合。
皮尔逊相关系数公式实际上就是在计算夹角余弦之前将两个向量减去各个样本的平均值,达到中心化的目的。是余弦相似度在维度缺失上的一种改进方法。
(3)基于皮尔逊系数的思路,还可以通过引入物品平均分的方式,减少物品评分偏置对结果的影响,如(式 2-3)所示。
其中, 代表物品 得到所有评分的平均分。
在相似用户的计算过程中,任何合理的“向量相似度定义方式”都可以作为相似用户计算的标准。通过对相似度定义的改进来解决传统的协同过滤算法存在的缺陷。
2.2.3 最终结果的排序#
在获得 Top n 相似用户之后,利用 Top n 用户生成最终推荐结果的过程如下。假设“目标用户与其相似用户的喜好是相似的”,可根据相似用户的已有评价对目标用户的偏好进行预测。最常用的方式是利用用户相似度和相似用户的评价的加权平均获得目标用户的评价预测,如(式 2-4)所示。
其中,权重 是用户 和用户 的相似度, 是用户 对物品 的评分。
在获得用户 对不同物品的评价预测后,最终的推荐列表根据预测得分进行排序即可得到。至此,完成协同过滤的全部推荐过程。
协同过滤算法基于用户相似度进行推荐,因此也被称为基于用户的协同过滤(UserCF),它符合人们直觉上的“兴趣相似的朋友喜欢的物品,我也喜欢”的思想,但从技术的角度,它也存在一些缺点,主要包括以下两点。
(1)在互联网应用的场景下,用户数往往远大于物品数,而 UserCF 需要维护用户相似度矩阵以便快速找出 Top n 相似用户。该用户相似度矩阵的存储开销非常大,而且随着业务的发展,用户数的增长会导致用户相似度矩阵的空间复杂度以 n² 的速度快速增长,这是在线存储系统难以承受的扩展速度。
(2)用户的历史数据向量往往非常稀疏,对于只有几次购买或者点击行为的用户来说,找到相似用户的准确度是非常低的,这导致 UserCF 不适用于那些正反馈获取较困难的应用场景(如酒店预定、大件商品购买等低频应用)。
2.2.4 ItemCF#
由于 UserCF 技术上的两点缺陷,无论是 Amazon,还是 Netflix,都没有采用 UserCF 算法,而采用了 ItemCF 算法实现其最初的推荐系统。
ItemCF 是基于物品相似度进行推荐的协同过滤算法。通过计算共现矩阵中物品列向量的相似度得到物品之间的相似矩阵,再找到用户的历史正反馈物品的相似物品进行进一步排序和推荐,具体步骤如下:
(1)基于历史数据,构建以用户(假设用户总数为 m)为行坐标,物品(物品总数为 n)为列坐标的 m×n 维的共现矩阵;
(2)计算共现矩阵两两列向量间的相似性(相似度的计算方式与用户相似度的计算方式相同),构建 n×n 维的物品相似度矩阵;
(3)获得用户历史行为数据中的正反馈物品列表;
(4)利用物品相似度矩阵,针对目标用户历史行为中的正反馈物品,找出相似的 Top k 个物品,组成相似物品集合;
(5)对相似物品集合中的物品,利用相似度分值进行排序,生成最终的推荐列表。
在第 5 步中,如果一个物品与多个用户行为历史中的正反馈物品相似,那么该物品最终的相似度应该是多个相似度的累加,如(式 2-5)所示。
其中, 是目标用户的正反馈物品集合, 是物品 与物品 的物品相似度, 是用户 对物品 的已有评分。
2.2.5 UserCF与ItemCF的应用场景#
由于 UserCF 基于用户相似度进行推荐,使其具备更强的社交特性,用户能够快速得知与自己兴趣相似的人最近喜欢的是什么,即使某个兴趣点以前不在自己的兴趣范围内,也有可能通过“朋友”的动态快速更新自己的推荐列表。这样的特点使其非常适用于新闻推荐场景。因为新闻本身的兴趣点往往是分散的,相比用户对不同新闻的兴趣偏好,新闻的及时性、热点性往往是其更重要的属性,而 UserCF 正适用于发现热点,以及跟踪热点的趋势。
ItemCF 更适用于兴趣变化较为稳定的应用,比如在 Amazon 的电商场景中,用户在一个时间段内更倾向于寻找一类商品,这时利用物品相似度为其推荐相关物品是契合用户动机的。在 Netflix 的视频推荐场景中,用户观看电影、电视剧的兴趣点往往比较稳定,因此利用 ItemCF 推荐风格、类型相似的视频是更合理的选择。
2.2.6 协同过滤的下一步发展#
协同过滤是一个非常直观、可解释性很强的模型,但它并不具备较强的泛化能力,换句话说,协同过滤无法将两个物品相似这一信息推广到其他物品的相似性计算上。这就导致了问题——热门的物品具有很强的头部效应,容易跟大量物品产生相似性;而尾部的物品由于特征向量稀疏,很少与其他物品产生相似性,导致很少被推荐。
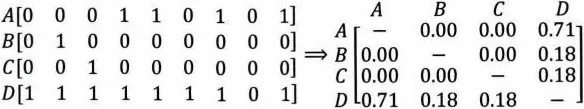
通过物品相似度矩阵可知,A、B、C 之间的相似度均为 0,而与 A、B、C 最相似的物品均为物品 D,因此在以 ItemCF 为基础构建的推荐系统中,物品 D 将被推荐给所有对 A、B、C 有过正反馈的用户。
但事实上,物品 D 与 A、B、C 相似的原因仅在于物品 D 是一件热门商品,系统无法找出 A、B、C 之间相似性的主要原因是其特征向量非常稀疏,缺乏相似性计算的直接数据。这一现象揭示了协同过滤的天然缺陷——推荐结果的头部效应较明显,处理稀疏向量的能力弱。
为解决上述问题,同时增加模型的泛化能力,矩阵分解技术被提出。该方法在协同过滤共现矩阵的基础上,使用更稠密的隐向量表示用户和物品,挖掘用户和物品的隐含兴趣和隐含特征,在一定程度上弥补了协同过滤模型处理稀疏矩阵能力不足的问题。
另外,协同过滤仅利用用户和物品的交互信息,无法有效地引入用户年龄、性别、商品描述、商品分类、当前时间等一系列用户特征、物品特征和上下文特征,这无疑造成了有效信息的遗漏。为了在推荐模型中引入这些特征,推荐系统逐渐发展到以逻辑回归模型为核心的、能够综合不同类型特征的机器学习模型的道路上。
2.3 矩阵分解算法——协同过滤的进化#
矩阵分解在协同过滤算法中“共现矩阵”的基础上,加入了隐向量的概念,加强了模型处理稀疏矩阵的能力。
Netflix 是美国最大的流媒体公司,其推荐系统的主要应用场景是利用用户的行为历史为用户推荐。
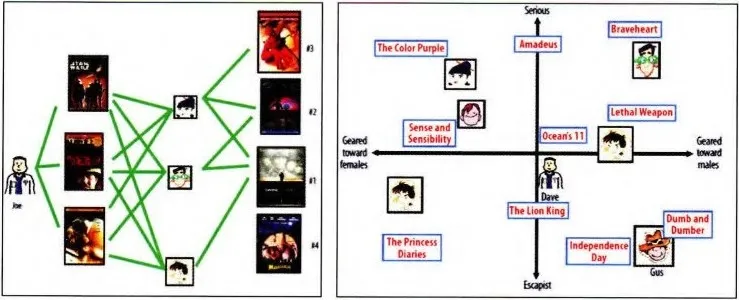
如图2-4 (a)所示,协同过滤算法找到用户可能喜欢的视频的方式很直接,即基于用户的观看历史,找到跟目标用户 Joe 看过同样视频的相似用户,然后找到这些相似用户喜欢看的其他视频,推荐给目标用户 Joe。
矩阵分解算法则期望为每一个用户和视频生成一个隐向量,将用户和视频定位到隐向量的表示空间上(如图 2-4(b)所示),距离相近的用户和视频表明兴趣特点接近,在推荐过程中,就应该把距离相近的视频推荐给目标用户。例如,如果希望为图 2-4(b)中的用户 Dave 推荐视频,可以发现离 Dave 的用户向量最近的两个视频向量分别是“Ocean’s 11”和“The Lion King”,那么可以根据向量距离由近到远的顺序生成 Dave 的推荐列表。
基础知识——什么是过拟合现象和正则化#
正则化对应的英文是 Regularization,直译过来是“规则化”,即希望让训练出的模型更“规则”、更稳定,避免预测出一些不稳定的“离奇”结果。
举例来说,图 2-6 中蓝色的点是样本点,红色的曲线是通过某模型学习出的拟合函数 ,红色曲线虽然很好地拟合了所有样本点,但波动的幅度非常大,很难想象真实世界的数据模式是红色曲线的样子,这就是直观上的“过拟合现象”。
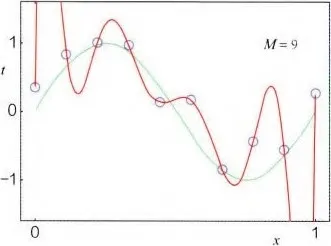
为了让模型更“稳重”,需要给模型加入一些限制,这些限制就是正则化项。在加入正则化项之后再次进行训练,拟合函数变成了绿色曲线的形式,避免受个别“噪声点”的影响,模型的预测输出更加稳定。
在矩阵分解算法中,由于隐向量的存在,使任意的用户和物品之间都可以得到预测分值。而隐向量的生成过程其实是对共现矩阵进行全局拟合的过程,因此隐向量其实是利用全局信息生成的,有更强的泛化能力;而对协同过滤来说,如果两个用户没有相同的历史行为,两个物品没有相同的人购买,那么这两个用户和两个物品的相似度都将为 0(因为协同过滤只能利用用户和物品自己的信息进行相似度计算,这就使协同过滤不具备泛化利用全局信息的能力)。
2.3.3 消除用户和物品打分的偏差#
由于不同用户的打分体系不同(比如在5分为满分的情况下,有的用户认为打 3 分已经是很低的分数了,而有的用户认为打 1 分才是比较差的评价),不同物品的衡量标准也有所区别(比如电子产品的平均分和日用品的平均分差异有可能比较大),为了消除用户和物品打分的偏差(Bias),常用的做法是在矩阵分解时加入用户和物品的偏差向量。
2.3.4 矩阵分解的优点和局限性#
优点:
(1)泛化能力强。在一定程度上解决了数据稀疏问题。
(2)空间复杂度低。不需再存储协同过滤模型服务阶段所需的“庞大”的用户相似性或物品相似性矩阵,只需存储用户和物品隐向量。空间复杂度由 n^2 级别降低到 (n+m)·k 级别。
(3)更好的扩展性和灵活性。矩阵分解的最终产出是用户和物品隐向量,这其实与深度学习中的 Embedding 思想不谋而合,因此矩阵分解的结果也非常便于与其他特征进行组合和拼接,并便于与深度学习网络进行无缝结合。
局限性:与协同过滤一样,矩阵分解同样不方便加入用户、物品和上下文相关的特征,这使得矩阵分解丧失了利用很多有效信息的机会,同时在缺乏用户历史行为时,无法有效推荐。为了解决这个问题,逻辑回归模型及其后续发展出的因子分解机等模型,凭借其天然的融合不同特征的能力,逐渐在推荐系统领域得到更广泛的应用。
2.4 逻辑回归——融合多种特征的推荐模型#
相比协同过滤模型仅利用用户与物品的相互行为信息进行推荐,逻辑回归模型能够综合利用用户、物品、上下文等多种不同的特征,生成较为“全面”的推荐结果。另外,逻辑回归的另一种表现形式“感知机”作为神经网络中最基础的单一神经元,是深度学习的基础性结构。
相比协同过滤和矩阵分解利用用户和物品的“相似度”进行推荐,逻辑回归将推荐问题看成一个分类问题,通过预测正样本的概率对物品进行排序。这里的正样本可以是用户“点击”了某商品,也可以是用户“观看”了某视频,均是推荐系统希望用户产生的“正反馈”行为。因此,逻辑回归模型将推荐问题转换成了一个点击率(Click Through Rate,CTR)预估问题。
2.4.1 基于逻辑回归模型的推荐流程#
基于逻辑回归的推荐过程如下:
(1)将用户年龄、性别、物品属性、物品描述、当前时间、当前地点等特征转换成数值型特征向量;
(2)确定逻辑回归模型的优化目标(以优化“点击率”为例),利用已有样本数据对逻辑回归模型进行训练,确定逻辑回归模型的内部参数;
(3)在模型服务阶段,将特征向量输入逻辑回归模型,经过逻辑回归模型的推断,得到用户“点击”(这里用点击作为推荐系统正反馈行为的例子)物品的概率;
(4)利用“点击”概率对所有候选物品进行排序,得到推荐列表;
基础知识——什么是梯度下降法#
梯度下降法是一个一阶最优化算法,也称为最速下降法。应用梯度下降法的目的是找到一个函数的局部极小值。为此,必须沿函数上当前点对应梯度(或者是近似梯度)的反方向进行规定步长距离的迭代搜索。如果向梯度正方向迭代进行搜索,则会接近函数的局部极大值点,这个过程被称为梯度上升法。
如图 2-9 所示,梯度下降法很像寻找一个盆地最低点的过程。那么,在寻找最低点的过程中,沿哪个方向才是下降最快的方向呢?
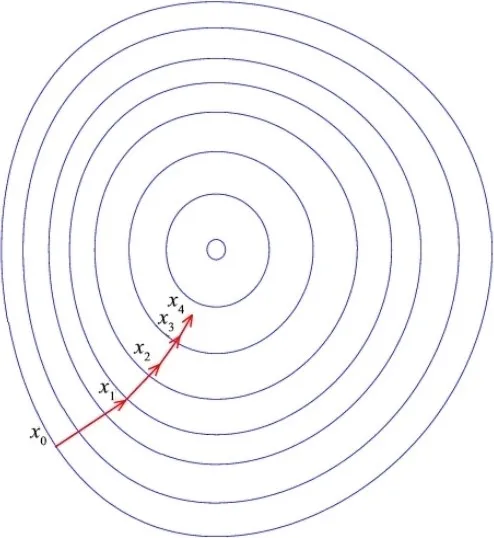
这就利用了“梯度”的性质:如果实值函数 在点 处可微且有定义,那么函数 在点 处沿着梯度相反的方向 下降最快。
因此,在优化某模型的目标函数时,只需对目标函数进行求导,得到梯度的方向,沿梯度的反方向下降,并迭代此过程直至寻找到局部最小点。
2.5 从FM到FFM——自动特征交叉的解决方案#
逻辑回归模型表达能力不强的问题,会不可避免地造成有效信息的损失。在仅利用单一特征而非交叉特征进行判断的情况下,有时不仅是信息损失的问题,甚至会得出错误的结论。著名的“辛普森悖论”用一个非常简单的例子,说明了进行多维度特征交叉的重要性。
基础知识——什么是辛普森悖论#
在对样本集合进行分组研究时,在分组比较中都占优势的一方,在总评中有时反而是失势的一方,这种有悖常理的现象,被称为“辛普森悖论”。下面用一个视频推荐的例子进一步说明什么是“辛普森悖论”。
假设表 2-1 和表 2-2 所示为某视频应用中男性用户和女性用户点击视频的数据。
表2-1 男性用户
| 视频 | 点击(次) | 曝光(次) | 点击率 |
|---|---|---|---|
| 视频A | 8 | 530 | 1.51% |
| 视频B | 51 | 1520 | 3.36% |
表2-2 女性用户
| 视频 | 点击(次) | 曝光(次) | 点击率 |
|---|---|---|---|
| 视频A | 201 | 2510 | 8.01% |
| 视频B | 92 | 1010 | 9.11% |
从以上数据中可以看出,无论男性用户还是女性用户,对视频 B 的点击率都高于视频 A,显然推荐系统应该优先考虑向用户推荐视频 B。
那么,如果忽略性别这个维度,将数据汇总(如表 2-3 所示)会得出什么结论呢?
表2-3 数据汇总
| 视频 | 点击(次) | 总曝光(次) | 点击率 |
|---|---|---|---|
| 视频A | 209 | 3040 | 6.88% |
| 视频B | 143 | 2530 | 5.65% |
在汇总结果中,视频 A 的点击率居然比视频 B 高。如果据此进行推荐,将得出与之前的结果完全相反的结论,这就是所谓的“辛普森悖论”。
在“辛普森悖论”的例子中,分组实验相当于使用“性别”+“视频 id”的组合特征计算点击率,而汇总实验则使用“视频 id”这一单一特征计算点击率。汇总实验对高维特征进行了合并,损失了大量的有效信息,因此无法正确刻画数据模式。
逻辑回归只对单一特征做简单加权,不具备进行特征交叉生成高维组合特征的能力,因此表达能力很弱,甚至可能得出像“辛普森悖论”那样的错误结论。因此,通过改造逻辑回归模型,使其具备特征交叉的能力是必要和迫切的。
基础知识——什么是one-hot编码#
one-hot 编码是将类别型特征转换成向量的一种编码方式。由于类别型特征不具备数值化意义,如果不进行 one-hot 编码,无法将其直接作为特征向量的一个维度使用。
举例来说,某样本有三个特征,分别是星期、性别和城市,用[Weekday=Tuesday,Gender=Male,City=London] 表示。由于模型的输入特征向量仅可以是数值型特征向量,无法把“Tuesday”这个字符串直接输入模型,需要将其数值化,最常用的方法就是将特征做 one-hot 编码。编码的结果如图 2-10 所示。
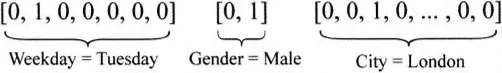
可以看到,Weekday 这个特征域有 7 个维度,Tuesday 对应第 2 个维度,所以把对应维度置为 1。Gender 分为 Male 和 Female,one-hot 编码就有两个维度,City 特征域同理。
虽然 one-hot 编码方式可以将类别型特征转变成数值型特征向量,但是会不可避免地造成特征向量中存在大量数值为 0 的特征维度。这在互联网这种海量用户场景下尤为明显。假设某应用有 1 亿用户,那么将用户 id 进行 one-hot 编码后,将造成 1 亿维特征向量中仅有 1 维是非零的。这是造成互联网模型的输入特征向量稀疏的主要原因。
第3章 浪潮之巅——深度学习在推荐系统中的应用#
在进入深度学习时代之后,推荐模型主要在以下两方面取得了重大进展。
(1)与传统的机器学习模型相比,深度学习模型的表达能力更强,能够挖掘出更多数据中潜藏的模式。
(2)深度学习的模型结构非常灵活,能够根据业务场景和数据特点,灵活调整模型结构,使模型与应用场景完美契合。
3.2 AutoRec——单隐层神经网络推荐模型#
AutoRec 模型是一个标准的自编码器,它的基本原理是利用协同过滤中的共现矩阵,完成物品向量或者用户向量的自编码。再利用自编码的结果得到用户对物品的预估评分,进而进行推荐排序。
基础知识——什么是自编码器#
自编码器是指能够完成数据“自编码”的模型。无论是图像、音频,还是数据,都可以转换成向量的形式进行表达。假设其数据向量为 r,自编码器的作用是将向量 r 作为输入,通过自编码器后,得到的输出向量尽量接近其本身。
在完成自编码器的训练后,就相当于在重建函数中存储了所有数据向量的“精华”。一般来说,重建函数的参数数量远小于输入向量的维度数量,因此自编码器相当于完成了数据压缩和降维的工作。
经过自编码器生成的输出向量,由于经过了自编码器的“泛化”过程,不会完全等同于输入向量,也因此具备了一定的缺失维度的预测能力,这也是自编码器能用于推荐系统的原因。
基础知识——什么是神经元、神经网络和梯度反向传播#
神经元(Neuron),又名感知机(Perceptron),在模型结构上与逻辑回归一致,这里以一个二维输入向量的例子对其进行进一步的解释。假设模型的输入向量是一个二维特征向量(x1, x2),则单神经元的模型结构如图 3-3 所示。
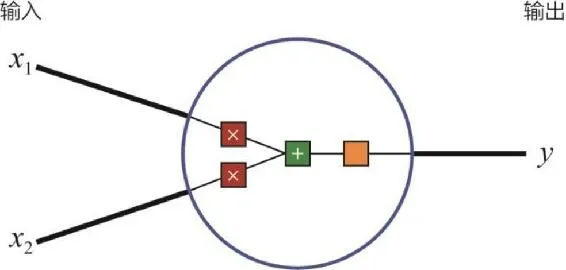
其中,蓝圈内的部分可以看作线性的加权求和,再加上一个常数偏置 b 的操作,最终得到输入如下。
图中的蓝圈可以看作激活函数,它的主要作用是把一个无界输入映射到一个规范的、有界的值域上。常用的激活函数除了 2.4 节介绍的 sigmoid 函数,还包括 tanh、ReLU 等。单神经元由于受到简单结构的限制,拟合能力不强,因此在解决复杂问题时,经常会用多神经元组成一个网络,使之具备拟合任意复杂函数的能力,这就是我们常说的神经网络。图 3-4 展示了一个由输入层、两神经元隐层和单神经元输出层组成的简单神经网络。
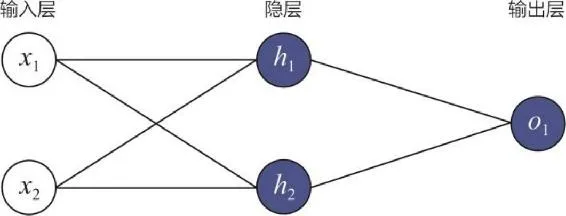
其中,蓝色神经元的构造与上面所述的感知机的构造相同, h1 和 h2 神经元的输入是由 x1 和 x2 组成的特征向量,而神经元 o1 的输入则是由 h1 和 h2 输出组成的输入向量。本例是最简单的神经网络,在深度学习的发展历程中,正是研究人员对神经元不同连接方式的探索,才衍生出各种不同特性的深度学习网络,让深度学习模型的家族树枝繁叶茂。
在清楚了神经网络的模型结构之后,重要的问题就是如何训练一个神经网络。这里需要用到神经网络的重要训练方法——前向传播(Forward Propagation)和反向传播。前向传播的目的是在当前网络参数的基础上得到模型对输入的预估值,也就是常说的模型推断过程。在得到预估值之后,就可以利用损失函数(Loss Function)的定义计算模型的损失。对输出层神经元来说(图中的 o1),可以直接利用梯度下降法计算神经元相关权重(即图 3-5 中的权重 w5 和 w6)的梯度,从而进行权重更新,但对隐层神经元的相关参数(比如 w1),应该如何利用输出层的损失进行梯度下降呢?
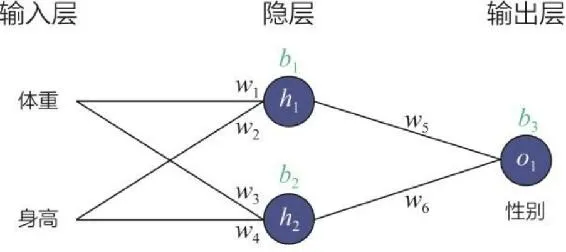
利用求导过程中的链式法则(Chain Rule),可以解决梯度反向传播的问题。如(式 3-4)所示,最终的损失函数到权重 w1 的梯度是由损失函数到神经元 h1 输出的偏导,以及神经元 h1 输出到权重 w1 的偏导相乘而来的。也就是说,最终的梯度逐层传导回来,“指导”权重 w1 的更新。
3.3 Deep Crossing模型——经典的深度学习架构#
Deep Crossing 模型的应用场景是微软搜索引擎 Bing 中的搜索广告推荐场景。用户在搜索引擎中输入搜索词之后,搜索引擎除了会返回相关结果,还会返回与搜索词相关的广告,这也是大多数搜索引擎的主要赢利模式。尽可能地增加搜索广告的点击率,准确地预测广告点击率,并以此作为广告排序的指标之一,是 Deep Crossing 模型的优化目标。
微软使用的特征如表3-1所示,这些特征可以分为三类:一类是可以被处理成one-hot或者multi-hot向量的类别型特征,包括用户搜索词(query)、广告关键词(keyword)、广告标题(title)、落地页(landing page)、匹配类型(match type);一类是数值型特征,微软称其为计数型(counting)特征,包括点击率、预估点击率(click prediction);一类是需要进一步处理的特征,包括广告计划(campaign)、曝光样例(impression)、点击样例(click)等。严格地说,这些都不是独立的特征,而是一个特征的组别,需要进一步处理。例如,可以将广告计划中的预算(budget)作为数值型特征,而广告计划的id则可以作为类别型特征。
表3-1 Deep Crossing模型使用的特征
| 特征 | 特征含义 |
|---|---|
| 搜索词 | 用户在搜索框中输入的搜索词 |
| 广告关键词 | 广告主为广告添加的描述其产品的关键词 |
| 广告标题 | 广告标题 |
| 落地页 | 点击广告后的落地页面 |
| 匹配类型 | 广告主选择的广告-搜索词匹配类型(包括精准匹配、短语匹配、语义匹配等) |
| 点击率 | 广告的历史点击率 |
| 预估点击率 | 另一个CTR模型的CTR预估值 |
| 广告计划 | 广告主创建的广告投放计划,包括预算、定向条件等 |
| 曝光样例 | 一个广告“曝光”的例子,该例子记录了广告在实际曝光场景中的相关信息 |
| 点击样例 | 一个广告“点击”的例子,该例子记录了广告在实际点击场景中的相关信息 |
3.6 Wide&Deep模型——记忆能力和泛化能力的综合#
“记忆能力”可以被理解为模型直接学习并利用历史数据中物品或者特征的“共现频率”的能力。一般来说,协同过滤、逻辑回归等简单模型有较强的“记忆能力”。由于这类模型的结构简单,原始数据往往可以直接影响推荐结果,产生类似于“如果点击过 A,就推荐 B”这类规则式的推荐,这就相当于模型直接记住了历史数据的分布特点,并利用这些记忆进行推荐。
因为 Wide&Deep 是由谷歌应用商店(Google Play)推荐团队提出的,所以这里以 App 推荐的场景为例,解释什么是模型的“记忆能力”。
假设在 Google Play 推荐模型的训练过程中,设置如下组合特征:AND (user_installed_app=netflix,impression_app=pandora)(简称 netflix&pandora),它代表用户已经安装了 netflix 这款应用,而且曾在应用商店中看到过 pandora 这款应用。如果以“最终是否安装 pandora”为数据标签(label),则可以轻而易举地统计出 netflix&pandora 这个特征和安装 pandora 这个标签之间的共现频率。假设二者的共现频率高达 10%(全局的平均应用安装率为 1%),这个特征如此之强,以至于在设计模型时,希望模型一发现有这个特征,就推荐 pandora 这款应用(就像一个深刻的记忆点一样印在脑海里),这就是所谓的模型的“记忆能力”。像逻辑回归这类简单模型,如果发现这样的“强特征”,则其相应的权重就会在模型训练过程中被调整得非常大,这样就实现了对这个特征的直接记忆。相反,对于多层神经网络来说,特征会被多层处理,不断与其他特征进行交叉,因此模型对这个强特征的记忆反而没有简单模型深刻。
“泛化能力”可以被理解为模型传递特征的相关性,以及发掘稀疏甚至从未出现过的稀有特征与最终标签相关性的能力。矩阵分解比协同过滤的泛化能力强,因为矩阵分解引入了隐向量这样的结构,使得数据稀少的用户或者物品也能生成隐向量,从而获得有数据支撑的推荐得分,这就是非常典型的将全局数据传递到稀疏物品上,从而提高泛化能力的例子。再比如,深度神经网络通过特征的多次自动组合,可以深度发掘数据中潜在的模式,即使是非常稀疏的特征向量输入,也能得到较稳定平滑的推荐概率,这就是简单模型所缺乏的“泛化能力”。
3.6.3 Wide&Deep模型的进化——Deep&Cross模型#
由多层交叉层组成的 Cross 网络在 Wide&Deep 模型中 Wide 部分的基础上进行特征的自动化交叉,避免了更多基于业务理解的人工特征组合。
3.8 注意力机制在推荐模型中的应用#
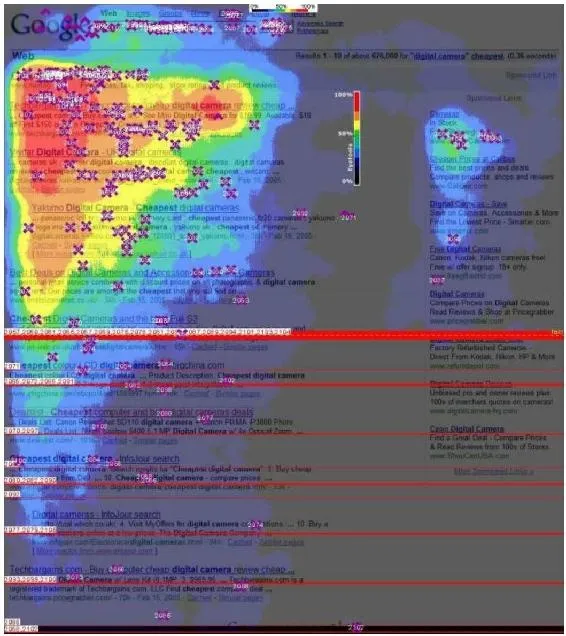
“注意力机制”来源于人类最自然的选择性注意的习惯。最典型的例子是用户在浏览网页时,会选择性地注意页面的特定区域,忽视其他区域。图 3-22 是谷歌搜索引擎对大量用户进行眼球追踪实验后得出的页面注意力热度图。可以看出,用户对页面不同区域的注意力分布的区别非常大。正是基于这样的现象,在建模过程中考虑注意力机制对预测结果的影响,往往会取得不错的收益。
近年来,注意力机制广泛应用于深度学习的各个领域,无论是在自然语言处理、语音识别还是计算机视觉领域,注意力模型都取得了巨大的成功。
3.8.1 AFM——引入注意力机制的FM#
在 NFM 模型中,不同域的特征 Embedding 向量经过特征交叉池化层的交叉,将各交叉特征向量进行“加和”,输入最后由多层神经网络组成的输出层。问题的关键在于加和池化(Sum Pooling)操作,它相当于“一视同仁”地对待所有交叉特征,不考虑不同特征对结果的影响程度,消解了大量有价值的信息。
这里“注意力机制”就派上了用场,它基于假设——不同的交叉特征对于结果的影响程度不同,以更直观的业务场景为例,用户对不同交叉特征的关注程度应是不同的。举例来说,如果应用场景是预测一位男性用户是否购买一款键盘的可能性,那么“性别=男且购买历史包含鼠标”这一交叉特征,很可能比“性别=男且用户年龄 = 30”这一交叉特征更重要,模型投入了更多的“注意力”在前面的特征上。正因如此,将注意力机制与 NFM 模型结合就显得理所应当了。
AFM 模型引入注意力机制是通过在特征交叉层和最终的输出层之间加入注意力网络(Attention Net)实现的。注意力网络的作用是为每一个交叉特征提供权重,也就是注意力得分。
3.8.3 注意力机制对推荐系统的启发#
注意力机制在数学形式上只是将过去的平均操作或加和操作换成了加权和或者加权平均操作。“注意力得分”的引入反映了人类天生的“注意力机制”特点。对这一机制的模拟,使得推荐系统更加接近用户真实的思考过程,从而达到提升推荐效果的目的。
从“注意力机制”开始,越来越多对深度学习模型结构的改进是基于对用户行为的深刻观察而得出的。相比学术界更加关注理论上的创新,业界的推荐工程师更需要基于对业务的理解推进推荐模型的演化。
3.9 DIEN——序列模型与推荐系统的结合#
3.9.1 DIEN的“进化”动机#
无论是电商购买行为,还是视频网站的观看行为,或是新闻应用的阅读行为,特定用户的历史行为都是一个随时间排序的序列。既然是时间相关的序列,就一定存在或深或浅的前后依赖关系,这样的序列信息对于推荐过程无疑是有价值的。但本章之前介绍的所有模型,有没有利用到这层序列信息呢?答案是否定的。即使是引入了注意力机制的 AFM 或 DIN 模型,也仅是对不同行为的重要性进行打分,这样的得分是时间无关的,是序列无关的。
那么,为什么说序列信息对推荐来说是有价值的呢?一个典型的电商用户的行为现象可以说明这一点。对于一个综合电商来说,用户兴趣的迁移其实非常快,例如,上周一位用户在挑选一双篮球鞋,这位用户上周的行为序列都会集中在篮球鞋这个品类的商品上,但在他完成购买后,本周他的购物兴趣可能变成买一个机械键盘。序列信息的重要性在于:
(1)它加强了最近行为对下次行为预测的影响。在这个例子中,用户近期购买机械键盘的概率会明显高于再买一双篮球鞋或购买其他商品的概率。
(2)序列模型能够学习到购买趋势的信息。在这个例子中,序列模型能够在一定程度上建立“篮球鞋”到“机械键盘”的转移概率。如果这个转移概率在全局统计意义上是足够高的,那么在用户购买篮球鞋时,推荐机械键盘也会成为一个不错的选项。直观上,二者的用户群体很有可能是一致的。
如果放弃序列信息,则模型学习时间和趋势这类信息的能力就不会那么强,推荐模型就仍然是基于用户所有购买历史的综合推荐,而不是针对“下一次购买”推荐。
兴趣进化网络分为三层,从下至上依次是:
(1)行为序列层(Behavior Layer,浅绿色部分):其主要作用是把原始的 id 类行为序列转换成 Embedding 行为序列。
(2)兴趣抽取层(Interest Extractor Layer,米黄色部分):其主要作用是通过模拟用户兴趣迁移过程,抽取用户兴趣。
(3)兴趣进化层(Interest Evolving Layer,浅红色部分):其主要作用是通过在兴趣抽取层基础上加入注意力机制,模拟与当前目标广告相关的兴趣进化过程。
在兴趣进化网络中,行为序列层的结构与普通的 Embedding 层是一致的,模拟用户兴趣进化的关键在于“兴趣抽取层”和“兴趣进化层”。
3.10 强化学习与推荐系统的结合#
强化学习(Reinforcement Learning)是近年来机器学习领域非常热门的研究话题,它的研究起源于机器人领域,针对智能体(Agent)在不断变化的环境(Environment)中决策和学习的过程进行建模。在智能体的学习过程中,会完成收集外部反馈(Reward),改变自身状态(State),再根据自身状态对下一步的行动(Action)进行决策,在行动之后持续收集反馈的循环,简称“行动-反馈-状态更新”的循环。
“智能体”的概念非常容易让人联想到机器人,整个强化学习的过程可以放到机器人学习人类动作的场景下理解。如果把推荐系统也当作一个智能体,把整个推荐系统学习更新的过程当作智能体“行动-反馈-状态更新”的循环,就能理解将强化学习的诸多理念应用于推荐系统领域并不是一件困难的事情。
3.10.1 深度强化学习推荐系统框架#
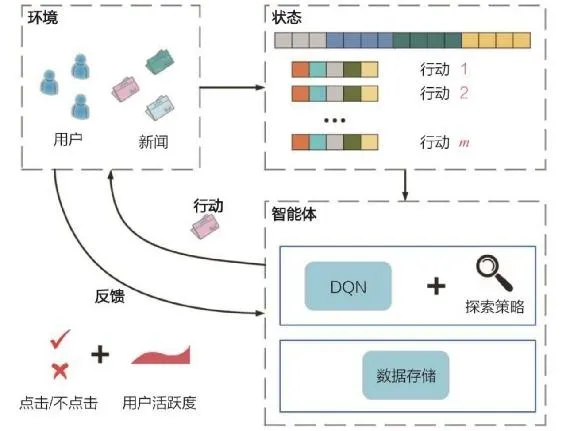
智能体:推荐系统本身,它包括基于深度学习的推荐模型、探索(explore)策略,以及相关的数据存储(memory)。
环境:由新闻网站或App、用户组成的整个推荐系统外部环境。在环境中,用户接收推荐的结果并做出相应反馈。
行动:对一个新闻推荐系统来说,“行动”指的就是推荐系统进行新闻排序后推送给用户的动作。
反馈:用户收到推荐结果后,进行正向的或负向的反馈。例如,点击行为被认为是一个典型的正反馈,曝光未点击则是负反馈的信号。此外,用户的活跃程度,用户打开应用的间隔时间也被认为是有价值的反馈信号。
状态:状态指的是对环境及自身当前所处具体情况的刻画。在新闻推荐场景中,状态可以被看作已收到所有行动和反馈,以及用户和新闻的所有相关信息的特征向量表示。站在传统机器学习的角度,“状态”可以被看作已收到的、可用于训练的所有数据的集合。
在这样的强化学习框架下,模型的学习过程可以不断地迭代,迭代过程主要有如下几步:
(1)初始化推荐系统(智能体)。
(2)推荐系统基于当前已收集的数据(状态)进行新闻排序(行动),并推送到网站或App(环境)中。
(3)用户收到推荐列表,点击或者忽略(反馈)某推荐结果。
(4)推荐系统收到反馈,更新当前状态或通过模型训练更新模型。
(5)重复第2步。
强化学习相比传统深度模型的优势就在于强化学习模型能够进行“在线学习”,不断利用新学到的知识更新自己,及时做出调整和反馈。
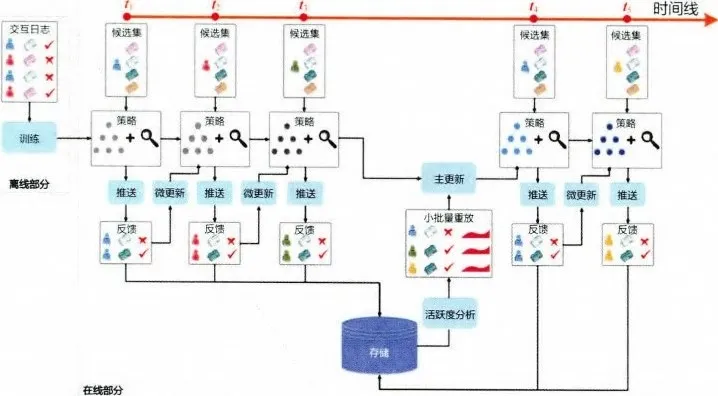
按照从左至右的时间顺序,依次描绘 DRN 学习过程中的重要步骤。
(1)在离线部分,根据历史数据训练好 DQN 模型,作为智能体的初始化模型。
(2)在 t1→t2 阶段,利用初始化模型进行一段时间的推送(push)服务,积累反馈(feedback)数据。
(3)在 t2 时间点,利用 t1→t2 阶段积累的用户点击数据,进行模型微更新(minor update)。
(4)在 t4 时间点,利用 t1→t4 阶段的用户点击数据及用户活跃度数据进行模型的主更新(major update)。
(5)重复第 2~4 步。
第4章 Embedding技术在推荐系统中的应用#
Embedding,中文直译为“嵌入”,常被翻译为“向量化”或者“向量映射”,Embedding 技术的应用非常广泛,将其称为深度学习的“基础核心操作”也不为过。它的主要作用是将稀疏向量转换成稠密向量,便于上层深度神经网络处理。
4.1 什么是Embedding#
Embedding 就是用一个低维稠密的向量“表示”一个对象(object),这里所说的对象可以是一个词、一个商品,也可以是一部电影。“表示”意味着 Embedding 向量能够表达相应对象的某些特征,同时向量之间的距离反映了对象之间的相似性。
4.1.1 词向量的例子#
Embedding 方法的流行始于自然语言处理领域对于词向量生成问题的研究。这里以词向量为例进一步解释 Embedding 的含义。
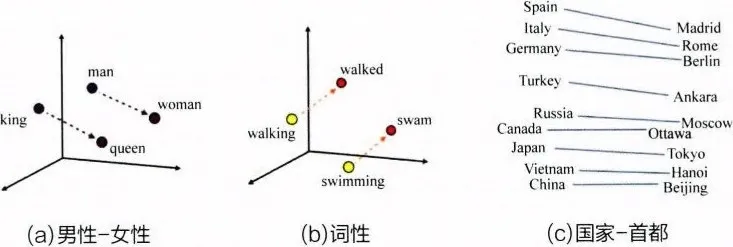
图 4-1(a)所示为使用 Word2Vec 方法编码的几个单词(带有性别特征)的 Embedding 向量在 Embedding 空间内的位置,可以看出从 Embedding(king)到 Embedding(queen),从 Embedding(man)到 Embedding(woman)的距离向量几乎一致,这表明词 Embedding 向量之间的运算甚至能够包含词之间的语义关系信息。同样,图 4-1(b)所示的词性例子中也反映出词向量的这一特点,Embedding (walking)到 Embedding(walked)和 Embedding(swimming)到 Embedding(swam)的距离向量一致,这表明 walking-walked 和 swimming-swam 的词性关系是一致的。
在有大量语料输入的前提下,Embedding 技术甚至可以挖掘出一些通用知识,如图 4-1(c)所示,Embedding(Madrid)-Embedding(Spain)≈Embedding(Beijing)-Embedding(China),这表明 Embedding 之间的运算操作可以挖掘出“首都-国家”这类通用的关系知识。
通过上面的例子可以知道,在词向量空间内,甚至在完全不知道一个词的向量的情况下,仅靠语义关系加词向量运算就可以推断出这个词的词向量。Embedding 就是这样从另外一个空间表达物品,同时揭示物品之间的潜在关系的,某种意义上讲,Embedding 方法甚至具备了本体论哲学层面上的意义。
4.1.2 Embedding技术在其他领域的扩展#
既然 Embedding 能够对“词”进行向量化,那么其他应用领域的物品也可以通过某种方式生成其向量化表示。
例如,如果对电影进行 Embedding,那么 Embedding(复仇者联盟)和 Embedding(钢铁侠)在 Embedding 向量空间内两点之间的距离就应该很近,而 Embedding(复仇者联盟)和 Embedding(乱世佳人)的距离会相对远。
同理,如果在电商领域对商品进行 Embedding,那么 Embedding(键盘)和 Embedding(鼠标)的向量距离应该比较近,而 Embedding(键盘)和 Embedding(帽子)的距离会相对远。
与词向量使用大量文本语料进行训练不同,不同领域的训练样本肯定是不同的,比如视频推荐往往使用用户的观看序列进行电影的 Embedding 化,而电商平台则会使用用户的购买历史作为训练样本。
4.1.3 Embedding技术对于深度学习推荐系统的重要性#
Embedding 对物品、用户相似度的计算是常用的推荐系统召回层技术。在局部敏感哈希(Locality-Sensitive Hashing)等快速最近邻搜索技术应用于推荐系统后,Embedding 更适用于对海量备选物品进行快速“初筛”,过滤出几百到几千量级的物品交由深度学习网络“精排”。
第5章 多角度审视推荐系统#
5.1 推荐系统的特征工程#
5.1.1 构建推荐系统特征工程的原则#
在推荐系统中,特征的本质其实是对某个行为过程相关信息的抽象表达。推荐过程中某个行为必须转换成某种数学形式才能被机器学习模型所学习,因此为了完成这种转换,就必须将这些行为过程中的信息以特征的形式抽取出来,用多个维度上的特征表达这一行为。
从具体的行为转化成抽象的特征,这一过程必然涉及信息的损失。一是因为具体的推荐行为和场景中包含大量原始的场景、图片和状态信息,保存所有信息的存储空间过大,无法在现实中满足;二是因为具体的推荐场景中包含大量冗余的、无用的信息,都考虑进来甚至会损害模型的泛化能力。搞清楚这两点后,就可以顺理成章地提出构建推荐系统特征工程的原则:
尽可能地让特征工程抽取出的一组特征能够保留推荐环境及用户行为过程中的所有有用信息,尽量摒弃冗余信息。
举例来说,在一个电影推荐的场景下,应该如何抽取特征才能代表“用户点击某个电影”这一行为呢?
为了回答这个问题,读者需要把自己置身于场景中,想象自己选择点击某个电影的过程受什么因素影响?笔者从自己的角度出发,按照重要性的高低列出了 6 个要素:
(1)自己对电影类型的兴趣偏好。
(2)该影片是否是流行的大片。
(3)该影片中是否有自己喜欢的演员和导演。
(4)电影的海报是否有吸引力。
(5)自己是否看过该影片。
(6)自己当时的心情。
秉着“保留行为过程中的所有有用信息”的原则,从电影推荐场景中抽取特征时,应该让特征能够尽量保留上述 6 个要素的信息。因此,要素、有用信息和数据抽取出的特征的对应关系如表 5-1 所示。
表5-1 要素、有用信息和数据抽取出的特征的对应关系
| 要素 | 有用信息和数据 | 特征 |
|---|---|---|
| 自己对电影类型的兴趣偏好 | 历史观看影片序列 | 影片id序列特征,或进一步抽取出兴趣Embedding特征 |
| 该影片是否是流行的大片 | 影片的流行分数 | 流行度特征 |
| 是否有自己喜欢的演员和导演 | 影片的元数据,即相关信息 | 元数据标签类特征 |
| 电影的海报是否有吸引力 | 影片海报的图像 | 图像内容类特征 |
| 自己是否看过该影片 | 用户观看历史 | 是否观看的布尔型特征 |
| 自己当时的心情 | 无法抽取 | 无 |
在抽取特征的过程中,必然存在着信息的损失,例如,“自己当时的心情”这个要素被无奈地舍弃了。再比如,用用户观看历史推断用户的“兴趣偏好”也一定会存在信息丢失的情况。因此,在已有的、可获得的数据基础上,“尽量”保留有用信息是一个现实的工程上的原则。
5.1.2 推荐系统中的常用特征#
- 用户行为数据
用户行为数据是推荐系统最常用,也是最关键的数据。用户的潜在兴趣、用户对物品的真实评价均包含在用户的行为历史中。用户行为在推荐系统中一般分为显性反馈行为(explicit feedback)和隐性反馈行为(implicit feedback)两种,在不同的业务场景中,则以不同的形式体现。表5-2所示为不同业务场景下用户行为数据的例子。
表5-2 不同业务场景下用户行为数据的例子
| 业务场景 | 显性反馈行为 | 隐性反馈行为 |
|---|---|---|
| 电子商务网站 | 对商品的评分 | 点击、加入购物车、购买等 |
| 视频网站 | 对视频的评分、点赞等 | 点击、播放、播放时长等 |
| 新闻类网站 | 赞、踩等行为 | 点击、评论等 |
| 音乐网站 | 对歌曲、歌手、专辑的评分 | 点击、播放、收藏等 |
对用户行为数据的使用往往涉及对业务的理解,不同的行为在抽取特征时的权重不同,而且一些跟业务特点强相关的用户行为需要推荐工程师通过自己的观察才能发现。
在当前的推荐系统特征工程中,隐性反馈行为越来越重要,主要原因是显性反馈行为的收集难度过大,数据量小。在深度学习模型对数据量的要求越来越大的背景下,仅用显性反馈的数据不足以支持推荐系统训练过程的最终收敛。因此,能够反映用户行为特点的隐性反馈是目前特征挖掘的重点。
在具体的用户行为类特征的处理上,往往有两种方式:一种是将代表用户行为的物品 id 序列转换成 multi-hot 向量,将其作为特征向量;另一种是预先训练好物品的 Embedding(可参考第 4 章介绍的 Embedding 方法),再通过平均或者类似于DIN模型(可参考3.8节)注意力机制的方法生成历史行为Embedding向量,将其作为特征向量。
- 用户关系数据
互联网本质上就是人与人、人与信息之间的连接。如果说用户行为数据是人与物之间的“连接”日志,那么用户关系数据就是人与人之间连接的记录。在互联网时代,人们最常说的一句话就是“物以类聚,人以群分”。用户关系数据毫无疑问是值得推荐系统利用的有价值信息。
用户关系数据也可以分为“显性”和“隐性”两种,或者称为“强关系”和“弱关系”。如图 5-1 所示,用户与用户之间可以通过“关注”“好友关系”等连接建立“强关系”,也可以通过“互相点赞”“同处一个社区”,甚至“同看一部电影”建立“弱关系”。
在推荐系统中,利用用户关系数据的方式不尽相同,可以将用户关系作为召回层的一种物品召回方式;也可以通过用户关系建立关系图,使用 Graph Embedding 的方法生成用户和物品的 Embedding;还可以直接利用关系数据,通过“好友”的特征为用户添加新的属性特征;甚至可以利用用户关系数据直接建立社会化推荐系统。
- 属性、标签类数据
这里把属性类和标签类数据归为一组进行讨论,因为本质上它们都是直接描述用户或者物品的特征。属性和标签的主体可以是用户,也可以是物品。他们的来源非常多样化,大体上包含表5-3中的几类。
表5-3 属性、标签类数据的分类和来源
| 主体 | 类别 | 来源 |
|---|---|---|
| 用户 | 人口属性数据(性别、年龄、住址等) 用户兴趣标签 | 用户注册信息、第三方 DMP(Data Management Platform,数据管理平台) 用户选择 |
| 物品 | 物品标签 物品属性(例如,商品的类别、价格;电影的分类、年代、演员、导演等信息) | 用户或者系统管理员添加 后台录入、第三方数据库 |
用户属性、物品属性、标签类数据是最重要的描述型特征。成熟的公司往往会建立一套用户和物品的标签体系,由专门的团队负责维护,典型的例子就是电商公司的商品分类体系;也可以有一些社交化的方法由用户添加。图 5-2 所示为豆瓣的“添加收藏”页面,在添加收藏的过程中,用户需要为收藏对象打上对应的标签,这是一种常见的社交化标签添加方法。
在推荐系统中使用属性、标签类数据,一般是通过 multi-hot 编码的方式将其转换成特征向量,一些重要的属性标签类特征也可以先转换成 Embedding,再输入推荐模型。
- 内容类数据
内容类数据可以看作属性标签型特征的延伸,它们同样是描述物品或用户的数据,但相比标签类特征,内容类数据往往是大段的描述型文字、图片,甚至视频。
一般来说,内容类数据无法直接转换成推荐系统可以“消化”的特征,需要通过自然语言处理、计算机视觉等技术手段提取关键内容特征,再输入推荐系统。例如,在图片类、视频类或是带有图片的信息流推荐场景中,往往会利用计算机视觉模型进行目标检测,抽取图片特征(如图 5-3 所示),再把这些特征(要素)转换成标签类数据,供推荐系统使用。
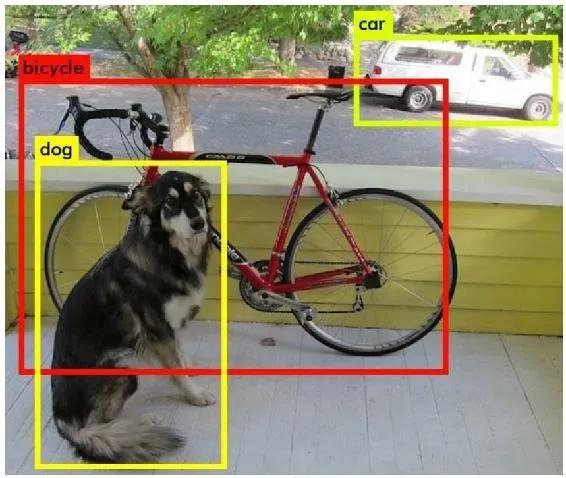
- 上下文信息
上下文信息(context)是描述推荐行为产生的场景的信息。最常用的上下文信息是“时间”和通过 GPS 获得的“地点”信息。根据推荐场景的不同,上下文信息的范围极广,包含但不限于时间、地点、季节、月份、是否节假日、天气、空气质量、社会大事件等信息。
引入上下文信息的目的是尽可能地保存推荐行为发生场景的信息。典型的例子是:在视频推荐场景中,用户倾向于在傍晚看轻松浪漫题材的电影,在深夜看悬疑惊悚题材的电影。如果不引入上下文特征,则推荐系统无法捕捉到与这些场景相关的有价值的信息。
- 统计类特征
统计类特征是指通过统计方法计算出的特征,例如历史 CTR、历史 CVR、物品热门程度、物品流行程度等。统计类特征一般是连续型特征,仅需经过标准化归一化等处理就可以直接输入推荐系统进行训练。
统计类特征本质上是一些粗粒度的预测指标。例如在 CTR 预估问题中,完全可以将某物品的历史平均 CTR 当作最简易的预测模型,但该模型的预测能力很弱,因此历史平均 CTR 往往仅被当作复杂 CTR 模型的特征之一。统计类特征往往与最后的预测目标有较强的相关性,因此是绝不应被忽视的重要特征类别。
- 组合类特征
组合类特征是指将不同特征进行组合后生成的新特征。最常见的是“年龄+性别”组成的人口属性分段特征(segment)。在早期的推荐系统中,推荐模型(比如逻辑回归)往往不具备特征组合的能力。但是随着更多深度学习推荐系统的提出,组合类特征不一定通过人工组合、人工筛选的方法选出,还可以交给模型进行自动处理。
5.1.3 常用的特征处理方法#
对推荐系统来说,模型的输入往往是由数字组成的特征向量。5.1.2 节提到的诸多特征类别中,有“年龄”“播放时长”“历史 CTR”这些可以由数字表达的特征,它们可以非常自然地成为特征向量中的一个维度。对于更多的特征来说,例如用户的性别、用户的观看历史,它们是如何转变成数值型特征向量的呢?本节将从连续型(continuous)特征和类别型(categorical)特征两个角度介绍常用的特征处理方法。
- 连续型特征
连续型特征的典型例子是上文提到的用户年龄、统计类特征、物品的发布时间、影片的播放时长等数值型的特征。对于这类特征的处理,最常用的处理手段包括归一化、离散化、加非线性函数等方法。
归一化的主要目的是统一各特征的量纲,将连续特征归一到[0,1]区间。也可以做 0 均值归一化,即将原始数据集归一化为均值为 0、方差为 1 的数据集。
离散化是通过确定分位数的形式将原来的连续值进行分桶,最终形成离散值的过程。离散化的主要目的是防止连续值带来的过拟合现象及特征值分布不均匀的情况。经过离散化处理的连续型特征和经过 one-hot 处理的类别型特征一样,都是以特征向量的形式输入推荐模型中的。
加非线性函数的处理方法,是直接把原来的特征通过非线性函数做变换,然后把原来的特征及变换后的特征一起加入模型进行训练的过程。常用的非线性函数包括 ,,。
加非线性函数的目的是更好地捕获特征与优化目标之间的非线性关系,增强这个模型的非线性表达能力。
- 类别型特征
类别型特征的典型例子是用户的历史行为数据、属性标签类数据等。它的原始表现形式往往是一个类别或者一个 id。这类特征最常用的处理方法是使用 one-hot 编码将其转换成一个数值向量,2.5 节的“基础知识”部分已经详细介绍了 one-hot 编码的具体过程,在 one-hot 编码的基础上,面对同一个特征域非唯一的类别选择,还可以采用 multi-hot 编码。
对类别特征进行 one-hot 或 multi-hot 编码的主要问题是特征向量维度过大,特征过于稀疏,容易造成模型欠拟合,模型的权重参数的数量过多,导致模型收敛过慢。因此,在 Embedding 技术成熟之后,被广泛应用在类别特征的处理上,先将类别型特征编码成稠密 Embedding 向量,再与其他特征组合,形成最终的输入特征向量。
基础知识——什么是multi-hot编码#
对历史行为序列类、标签特征等数据来说,用户往往会与多个物品产生交互行为,或者被打上多个同类别标签,这时最常用的特征向量生成方式就是把其转换成 multi-hot 编码。
举例来说,某电商网站共有 10000 种商品,用户购买过其中的 10 种,那么用户的历史行为数据就可以转换成一个 10000 维的数值向量,其中仅有 10 个已购买商品对应的维度是 1,其余维度均为 0,这就是 multi-hot 编码。
5.2 推荐系统召回层的主要策略#
召回阶段负责将海量的候选集快速缩小为几百到几千的规模。
排序阶段则负责对缩小后的候选集进行精准排序。
5.2.1 召回层和排序层的功能特点#
推荐系统的模型部分将推荐过程分成召回层和排序层的主要原因是基于工程上的考虑。在排序阶段,一般会使用复杂模型,利用多特征进行精准排序,而在这一过程中,如果直接对百万量级的候选集进行逐一推断,则计算资源和延迟都是在线服务过程无法忍受的。因此加入召回过程,利用少量的特征和简单的模型或规则进行候选集的快速筛选(如图5-4所示),减少精准排序阶段的时间开销。
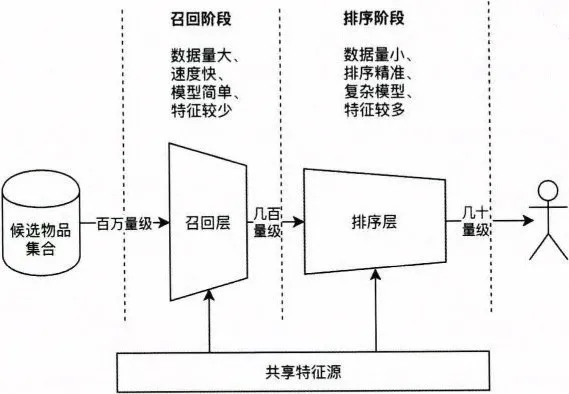
结合召回层、排序层的设计初衷和图5-4所示的系统结构,可以总结出召回层和排序层的如下特点:
- 召回层:待计算的候选集合大、速度快、模型简单、特征较少,尽量让用户感兴趣的物品在这个阶段能够被快速召回,即保证相关物品的召回率。
- 排序层:首要目标是得到精准的排序结果。需处理的物品数量少,可利用较多特征,使用比较复杂的模型。
在设计召回层时,“计算速度”和“召回率”其实是矛盾的两个指标,为提高“计算速度”,需要使召回策略尽量简单;而为了提高“召回率”,要求召回策略能够尽量选出排序模型需要的候选集,这又要求召回策略不能过于简单,导致召回物品无法满足排序模型的要求。
在权衡计算速度和召回率后,目前工业界主流的召回方法是采用多个简单策略叠加的“多路召回策略”。
5.2.2 多路召回策略#
所谓“多路召回策略”,就是指采用不同的策略、特征或简单模型,分别召回一部分候选集,然后把候选集混合在一起供后续排序模型使用的策略。
可以明显地看出,“多路召回策略”是在“计算速度”和“召回率”之间进行权衡的结果。其中,各简单策略保证候选集的快速召回,从不同角度设计的策略保证召回率接近理想的状态,不至于损害排序效果。
图 5-5 以某信息流应用为例,展示了其常用的多路召回策略,包括“热门新闻”“兴趣标签”“协同过滤”“最近流行”“朋友喜欢”等多种召回方法。其中,既包括一些计算效率高的简单模型(如协同过滤);也包括一些基于单一特征的召回方法(如兴趣标签),还包括一些预处理好的召回策略(如热门新闻、最近流行等)。
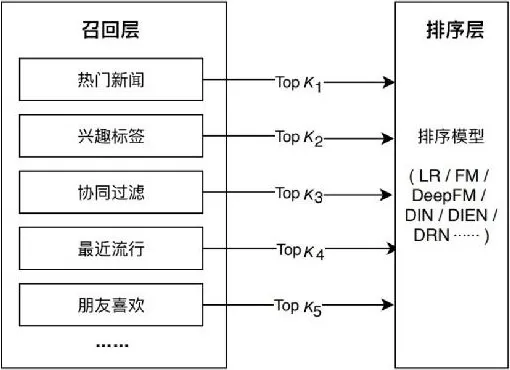
事实上,召回策略的选择与业务强相关。对视频推荐来说,召回策略可以是“热门视频”“导演召回”“演员召回”“最近上映”“流行趋势”“类型召回”等。
每一路召回策略会拉回 K 个候选物品,对于不同的召回策略,K 值可以选择不同的大小。这里的 K 值是超参数,一般需要通过离线评估加线上 A/B 测试的方式确定合理的取值范围。
虽然多路召回是实用的工程方法,但从策略选择到候选集大小参数的调整都需要人工参与,策略之间的信息也是割裂的,无法综合考虑不同策略对一个物品的影响。
5.2.3 基于Embedding的召回方法#
4.5 节曾详细介绍了 YouTube 推荐系统中利用深度学习网络生成的 Embedding 作为召回层的方法。再加上可以使用局部敏感哈希进行快速的 Embedding 最近邻计算,基于 Embedding 的召回方法在效果和速度上均不逊色于多路召回。
事实上,多路召回中使用“兴趣标签”“热门度”“流行趋势”“物品属性”等信息都可以作为 Embedding 召回方法中的附加信息(side information)融合进最终的 Embedding 向量中(典型的例子是 4.4 节介绍的 EGES Embedding 方法)。就相当于在利用 Embedding 召回的过程中,考虑到了多路召回的多种策略。
Embedding 召回的另一个优势在于评分的连续性。多路召回中不同召回策略产生的相似度、热度等分值不具备可比性,无法据此决定每个召回策略放回候选集的大小。Embedding 召回可以把 Embedding 间的相似度作为唯一的判断标准,因此可以随意限定召回的候选集大小。
生成 Embedding 的方法也绝不是唯一的,除了第 4 章介绍的 Item2Vec、Graph Embedding 等方法,矩阵分解、因子分解机等简单模型也完全可以得出用户和物品的 Embedding 向量。在实际应用中可以根据效果确定最优的召回层 Embedding 的生成方法。
5.3 推荐系统的实时性#
5.3.1 为什么说推荐系统的实时性是重要的#
从机器学习的角度讲,推荐系统实时性的重要之处体现在以下两个方面:
(1)推荐系统的更新速度越快,代表用户最近习惯和爱好的特征更新越快,越能为用户进行更有时效性的推荐。
(2)推荐系统更新得越快,模型越容易发现最新流行的数据模式(data pattern),越能让模型快速抓住最新的流行趋势。
这两方面的原因直接对应着推荐系统实时性的两大要素:一是推荐系统“特征”的实时性;二是推荐系统“模型”的实时性。
5.3.2 推荐系统“特征”的实时性#
推荐系统特征的实时性指的是“实时”地收集和更新推荐模型的输入特征,使推荐系统总能使用最新的特征进行预测和推荐。
举例来说,在一个短视频应用中,某用户完整地看完了一个长度为 10 分钟的“羽毛球教学”视频。毫无疑问,该用户对“羽毛球”这个主题是感兴趣的。系统希望立刻为用户继续推荐“羽毛球”相关的视频。但是由于系统特征的实时性不强,用户的观看历史无法实时反馈给推荐系统,导致推荐系统得知该用户看过“羽毛球教学”这个视频已经是半个小时之后了,此时用户已经离开该应用,无法继续推荐。这就是一个因推荐系统实时性差导致推荐失败的例子。
诚然,在用户下次打开该应用时,推荐系统可以利用上次的用户历史继续推荐“羽毛球”相关的视频,但毫无疑问,该推荐系统丧失了最可能增加用户黏性和留存度的时机。
为了说明增强“特征”实时性的具体方法,笔者在推荐系统的数据流架构图之上(如图 5-7 所示),来说明影响“特征”实时性的三个主要阶段。
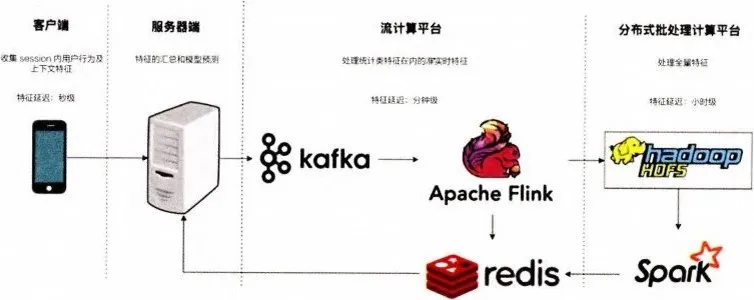
- 客户端实时特征
客户端是最接近用户的环节,也是能够实时收集用户会话内行为及所有上下文特征的地方。在经典的推荐系统中,利用客户端收集时间、地点、推荐场景等上下文特征,然后让这些特征随 http 请求一起到达服务器端是常用的请求推荐结果的方式。但容易被忽视的一点是客户端还是能够实时收集 session(会话)内用户行为的地方。
拿新闻类应用来说,用户在一次会话中(假设会话时长 3 分钟)分别点击并阅读了三篇文章。这三篇文章对推荐系统来说是至关重要的,因为它们代表了该用户的即时兴趣。如果能根据用户的即时兴趣实时地改变推荐结果,那对新闻应用来说将是很好的用户体验。
如果采用传统的流计算平台(图 5-7 中的 Flink),甚至批处理计算平台(图 5-7 中的 Spark),则由于延迟问题,系统可能无法在 3 分钟之内就把 session 内部的行为历史存储到特征数据库(如 Redis)中,这就导致用户的推荐结果不会马上受到 session 内部行为的影响,无法做到推荐结果的实时更新。
如果客户端能够缓存 session 内部的行为,将其作为与上下文特征同样的实时特征传给推荐服务器,那么推荐模型就能够实时地得到 session 内部的行为特征,进行实时的推荐。这就是利用客户端实时特征进行实时推荐的优势所在。
- 流计算平台的准实时特征处理
随着 Storm、Spark Streaming、Flink 等一批非常优秀的流计算平台的日益成熟,利用流计算平台进行准实时的特征处理几乎成了当前推荐系统的标配。所谓流计算平台,是将日志以流的形式进行微批处理(mini batch)。由于每次需要等待并处理一小批日志,流计算平台并非完全实时的平台,但它的优势是能够进行一些简单的统计类特征的计算,比如一个物品在该时间窗口内的曝光次数,点击次数、一个用户在该时间窗口内的点击话题分布,等等。
流计算平台计算出的特征可以立刻存入特征数据库供推荐模型使用。虽然无法实时地根据用户行为改变用户结果,但分钟级别的延迟基本可以保证推荐系统能够准实时地引入用户的近期行为。
- 分布式批处理平台的全量特征处理
随着数据最终到达以 HDFS 为主的分布式存储系统,Spark 等分布式批处理计算平台终于能够进行全量特征的计算和抽取了。在这个阶段着重进行的还有多个数据源的数据联结(join)及延迟信号的合并等操作。
用户的曝光、点击、转化数据往往是在不同时间到达 HDFS 的,有些游戏类应用的转化数据延迟甚至高达几个小时,因此只有在全量数据批处理这一阶段才能进行全部特征及相应标签的抽取和合并。也只有在全量特征准备好之后,才能够进行更高阶的特征组合的工作。这往往是无法在客户端和流计算平台上进行的。
分布式批处理平台的计算结果的主要用途是:
(1)模型训练和离线评估。
(2)特征保存入特征数据库,供之后的线上推荐模型使用。
数据从产生到完全进入 HDFS,再加上 Spark 的计算延迟,这一过程的总延迟往往达到小时级别,已经无法进行所谓的“实时”推荐,因此更多的是保证推荐系统特征的全面性,以便在用户下次登录时进行更准确的推荐。
5.3.3 推荐系统“模型”的实时性#
与“特征”的实时性相比,推荐系统“模型”的实时性往往是从更全局的角度考虑问题。特征的实时性力图用更准确的特征描述用户、物品和相关场景,从而让推荐系统给出更符合当时场景的推荐结果。而模型的实时性则是希望更快地抓住全局层面的新数据模式,发现新的趋势和相关性。
以某电商网站“双 11”的大量促销活动为例,特征的实时性会根据用户最近的行为更快地发现用户可能感兴趣的商品,但绝对不会发现一个刚刚流行起来的爆款商品、一个刚刚开始的促销活动,以及与该用户相似的人群最新的偏好。要发现这类全局性的数据变化,需要实时地更新推荐模型。
模型的实时性是与模型的训练方式紧密相关的,如图 5-8 所示,模型的实时性由弱到强的训练方式分别是全量更新、增量更新和在线学习(Online Learning)。
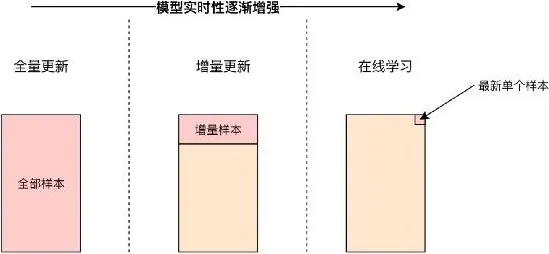
- 全量更新
“全量更新”是指模型利用某时间段内的所有训练样本进行训练。全量更新是最常用的模型训练方式,但它需要等待所有训练数据都“落盘”(记录在 HDFS 等大数据存储系统中)才可进行,并且训练全量样本的时间往往较长,因此全量更新也是实时性最差的模型更新方式。与之相比,“增量更新”的训练方式可以有效提高训练效率。
- 增量更新
增量更新仅将新加入的样本“喂”给模型进行增量训练。从技术上讲,深度学习模型往往采用随机梯度下降(SGD)法及其变种进行学习,模型对增量样本的学习相当于在原有样本的基础上继续输入增量样本进行梯度下降。增量更新的缺点是:增量更新的模型往往无法找到全局最优点,因此在实际的推荐系统中,经常采用增量更新与全局更新相结合的方式,在进行了几轮增量更新后,在业务量较小的时间窗口进行全局更新,纠正模型在增量更新过程中积累的误差。
- 在线学习
在线学习是进行模型实时更新的主要方法,也就是在获得一个新的样本的同时更新模型。与增量更新一样,在线学习在技术上也通过 SGD 的训练方式实现,但由于需要在线上环境进行模型的训练和大量模型相关参数的更新和存储,工程上的要求相对比较高。
在线学习的另一个附带问题是模型的稀疏性不强,例如,在一个输入特征向量达到几百万维的模型中,如果模型的稀疏性好,就可以在模型效果不受影响的前提下,仅让极小一部分特征对应的权重非零,从而让上线的模型体积很小(因为可以摒弃所有权重为 0 的特征),这有利于加快整个模型服务的过程。但如果使用 SGD 的方式进行模型更新,相比 batch 的方式,容易产生大量小权重的特征,这就增大了模型体积,从而增大模型部署和更新的难度。为了在在线学习过程中兼顾训练效果和模型稀疏性,有大量相关的研究,最著名的包括微软的 FOBOS、谷歌的 FTRL等。
在线学习的另一个方向是将强化学习与推荐系统结合,在 3.10 节介绍的强化学习推荐模型 DRN 中,应用了一种竞争梯度下降算法,它通过“随机探索新的深度学习模型参数,并根据实时效果反馈进行参数调整”的方法进行在线学习,这是在强化学习框架下提高模型实时性的有效尝试。
- 局部更新
大致思路是降低训练效率低的部分的更新频率,提高训练效率高的部分的更新频率。这种方式的代表是 Facebook 的“GBDT+LR”模型。
2.6 节已经介绍过“GBDT+LR”的模型结构,模型利用 GBDT 进行自动化的特征工程,利用 LR 拟合优化目标。GBDT 是串行的,需要依次训练每一棵树,因此训练效率低,更新的周期长,如果每次都同时训练“GBDT+LR”整个模型,那么 GBDT 的低效问题将拖慢 LR 的更新速度。为了兼顾 GBDT 的特征处理能力和 LR 快速拟合优化目标的能力,Facebook 采取的部署方法是每天训练一次 GBDT 模型,固定 GBDT 模型后,实时训练 LR 模型以快速捕捉数据整体的变化。通过模型的局部更新,做到 GBDT 和 LR 能力的权衡。
“模型局部更新”的做法较多应用在“Embedding 层+神经网络”的深度学习模型中,Embedding 层参数由于占据了深度学习模型参数的大部分,其训练过程会拖慢模型整体的收敛速度,因此业界往往采用 Embedding 层单独预训练,Embedding 层以上的模型部分高频更新的混合策略,这也是“模型局部更新”思想的又一次应用。
- 客户端模型实时更新
客户端模型实时更新在推荐系统业界仍处于探索阶段。对于一些计算机视觉类的模型,可以通过模型压缩的方式生成轻量级模型,部署于客户端,但对于推荐模型这类“重量级”的模型,往往需要依赖服务器端较强大的计算资源和丰富的特征数据进行模型服务。但客户端往往可以保存和更新模型一部分的参数和特征,比如当前用户的 Embedding 向量。
这里的逻辑和动机是,在深度学习推荐系统中,模型往往要接受用户 Embedding 和物品 Embedding 两个关键的特征向量。对于物品 Embedding 的更新,一般需要全局的数据,因此只能在服务器端进行更新;而对用户 Embedding 来说,则更多依赖用户自身的数据。那么把用户 Embedding 的更新过程移植到客户端来做,能实时地把用户最近的行为数据反映到用户的 Embedding 中来,从而可以在客户端通过实时改变用户 Embedding 的方式完成推荐结果的实时更新。
用简单例子说明。如果用户 Embedding 是由用户点击过的物品 Embedding 进行平均得到的,那么最先得到用户最新点击物品信息的客户端,就可以根据用户点击物品的 Embedding 实时更新用户 Embedding,并保存该 Embedding。在下次推荐时,将更新后的用户 Embedding 传给服务器,服务器端可根据最新的用户 Embedding 返回实时推荐内容。
5.4 如何合理设定推荐系统中的优化目标#
对一家商业公司而言,在绝大多数情况下,推荐系统的目标都是完成某个商业目标,所以根据公司的商业目标来制定推荐系统的优化目标理应作为“合理”的战略性目标。
5.4.1 YouTube以观看时长为优化目标的合理性#
1.1 节中,笔者就以 YouTube 推荐系统为例,强调了推荐系统在实现公司商业目标增长过程中扮演的关键角色。
YouTube 的主要商业模式是免费视频带来的广告收入,它的视频广告会阶段性地出现在视频播放之前和视频播放的过程中,因此 YouTube 的广告收入是与用户观看时长成正比的。为了完成公司的商业目标,YouTube 推荐系统的优化目标并不是点击率、播放率等通常意义上的 CTR 预估类的优化目标,而是用户的播放时长。
不可否认的是,点击率等指标与用户播放时长有相关性,但二者之间仍存在一些“优化动机”上的差异。如果以点击率为优化目标,那么推荐系统会倾向于推荐“标题党”“预览图劲爆”的短视频,而如果以播放时长为优化目标,那么推荐系统应将视频的长短、视频的质量等特征考虑进来,此时推荐一个高质量的“电影”或“连续剧”就是更好的选择。推荐目标的差异会导致推荐系统倾向性的不同,进而影响到能否完成“增加用户播放时长”这一商业目标。
在 YouTube 的推荐系统排序模型(如图 5-9 所示)中,引入播放时长作为优化目标的方式非常巧妙。YouTube 排序模型原本是把推荐问题当作分类问题对待的,即预测用户是否点击某个视频。
既然是分类问题,理论上应很难预测播放时长(预测播放时长应该是回归模型做的事情)。但 YouTube 巧妙地把播放时长转换成正样本的权重,输出层利用加权逻辑回归(Weighted Logistic)进行训练,预测过程中利用 算式计算样本的概率(Odds),这一概率就是模型对播放时长的预测(这里的论证并不严谨,在 8.3 节中还会进一步讨论 YouTube 排序模型的推断过程)。
5.4.2 模型优化和应用场景的统一性#
在天猫、淘宝等电商类网站上做推荐,用户从登录到购买的过程可以抽象成两步:
(1)产品曝光,用户浏览商品详情页。
(2)用户产生购买行为。
对电商类网站而言,公司的商业目标是通过推荐使用户产生更多的购买行为,电商类推荐模型应该是一个 CVR 预估模型。
由于购买转化行为是在第二步产生的,因此在训练 CVR 模型时,直观的做法是采用点击数据+转化数据(图 5-10 中灰色和深灰色区域数据)训练 CVR 模型。在使用 CVR 模型时,因为用户登录后直接看到的并不是具体的商品详情页,而是首页或者列表页,因此 CVR 模型需要在产品曝光的场景(图 5-10 中最外层圈内的数据)下进行预估。这就导致了训练场景与预估场景不一致的问题。模型在不同的场景下肯定会产生有偏的预估结果,进而导致应用效果的损失。
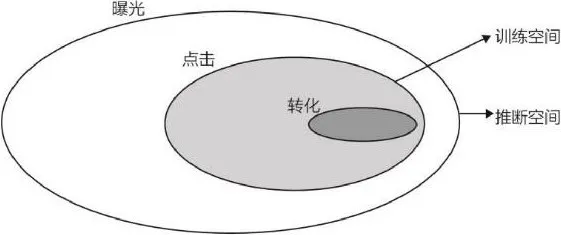
这里当然可以换个思路解决问题,即针对第一步的场景,构建 CTR 预估模型;再针对第二步的场景,构建 CVR 预估模型,针对不同的应用场景应用不同的预估模型,这也是电商或广告类公司经常采用的做法。但这个方案的尴尬之处在于 CTR 模型与最终优化目标的脱节,因为整个问题最终的优化目标是“购买转化”,并不是“点击”,在第一步过程中仅考虑点击数据,显然并不是全局最优化转化率的方案。
为了达到同时优化 CTR 和 CVR 模型的目的,阿里巴巴提出了多目标优化模型 ESMM(Entire Space Multi-task Model)。ESMM 可以被当作一个同时模拟“曝光到点击”和“点击到转化”两个阶段的模型。
从模型结构上看,底层的 Embedding 层是 CVR 部分和 CTR 部分共享的,共享 Embedding 层的目的主要是解决 CVR 任务正样本稀疏的问题,利用 CTR 的数据生成更准确的用户和物品的特征表达。
中间层是 CVR 部分和 CTR 部分各自利用完全隔离的神经网络拟合自己的优化目标——pCVR(post-click CVR,点击后转化率)和 pCTR(post-view Click-through Rate,曝光后点击率)。最终,将 pCVR 和 pCTR 相乘得到 pCTCVR。
5.5 推荐系统中比模型结构更重要的是什么#
5.5.1 有解决推荐问题的“银弹”吗#
DIEN 的要点是模拟并表达用户兴趣进化的过程,那么模型应用的前提必然是应用场景中存在着“兴趣进化”的过程。阿里巴巴的场景非常好理解,用户的购买兴趣在不同时间点有变化。比如用户在购买了笔记本电脑后会有一定概率购买其周边产品;用户在购买了某些类型的服装后会有一定概率选择与其搭配的其他服装,这些都是兴趣进化的直观例子。
DIEN 能够在阿里巴巴的应用场景有效的另一个原因是用户的兴趣进化路径能够被整个数据流近乎完整地保留。作为中国最大的电商集团,阿里巴巴各产品线组成的产品矩阵几乎能够完整地抓住用户购买兴趣迁移的过程。当然,用户有可能去京东、拼多多等电商平台购物,从而打断在阿里巴巴购物的兴趣进化过程,但从统计意义上讲,大量用户的兴趣进化过程还是可以被阿里巴巴的数据体系捕获的。
5.5.2 Netflix对用户行为的观察#
Netflix 是美国最大的流媒体公司,其推荐系统会根据用户的喜好生成影片的推荐列表。除了影片的排序,最能影响点击率的要素其实是影片的海报预览图。举例来说,一位喜欢马特·达蒙(美国著名男影星)的用户,当看到影片的海报上有马特·达蒙的头像时,点击该影片的概率会大幅增加。Netflix 的数据科学家在通过 A/B 测试验证这一点后,着手开始对影片预览图的生成进行优化(如图 5-13 所示),以提高推荐结果整体的点击率。

在具体的优化过程中,模型会根据不同用户的喜好,使用不同的影片预览图模板,填充以不同的前景、背景、文字等。通过使用简单的线性“探索与利用”(Exploration&Exploitation)模型验证哪种组合才是最适合某类用户的个性化海报。
在这个问题中,Netflix 并没有使用复杂的模型,但 CTR 提升的效果是 10% 量级的,远远超过改进推荐模型结构带来的收益。这才是从用户和场景出发解决问题。这也符合 5.3 节提出的“木桶理论”的思想,对推荐系统效果的改进,最有效的方法不是执着地改进那块已经很长的木板,而是发现那块最短的木板,提高整体的效果。
5.5.3 观察用户行为,在模型中加入有价值的用户信息#
再举一个例子,图5-14是美国最大的Smart TV(智能电视)平台Roku的主页,每一行是一个类型的影片。但对一个新用户来说,系统非常缺少关于他的点击和播放样本。那么对 Roku 的工程师来说,能否找到其他有价值的信息来解决数据稀疏问题呢?
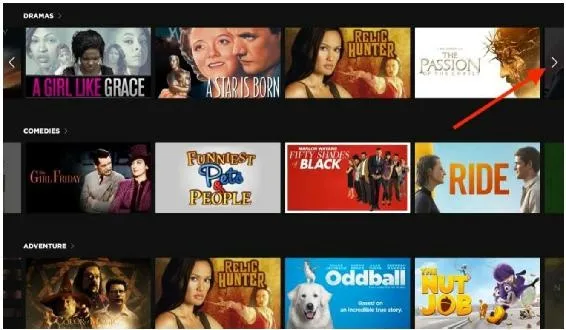
这就要求我们回到产品中,从用户的角度理解这个问题,发现有价值的信号。针对该用户界面来说,如果用户对某个类型的影片感兴趣,则必然会向右滑动鼠标或者遥控器(如图 5-14 中红色箭头所指),浏览这个类型下其他影片,这个滑动的动作很好地反映了用户对某类型影片的兴趣。
引入这个动作,无疑对构建用户兴趣向量,解决数据稀疏问题,进而提高推荐系统的效果有正向的作用。广义上讲,引入新的有价值信息相当于为推荐系统增加新的“水源”,而改进模型结构则是对已有“水源”的进一步挖掘。通常,新水源带来的收益更高,开拓难度却小于对已有水源的持续挖掘。
5.5.5 算法工程师不能只是一个“炼金术士”#
很多算法工程师把自己的工作戏称为“调参师”“炼金术士”,在深度学习的场景下,超参数的选择当然是不可或缺的工作。但如果算法工程师仅专注于是否在网络中加dropout,要不要更改激活函数(activation function),需不需要增加正则化项,以及修改网络深度和宽度,是不可能做出真正符合应用场景的针对性改进的。
很多业内同仁都说做推荐系统就是“揣摩人心”,这句话笔者并不完全赞同,但这在一定程度上反映了本节的主题——从用户的角度思考问题,构建模型。
如果阅读本书的你已经有了几年工作经验,对机器学习的相关技术已经驾轻就熟,反而应该从技术中跳出来,站在用户的角度,深度体验他们的想法,发现他们想法中的偏好和习惯,再用机器学习工具去验证它、模拟它,会得到意想不到的效果。
5.6 冷启动的解决办法#
任何推荐系统都要经历数据从无到有、从简单到丰富的过程。那么,在缺乏有价值数据的时候,如何有效推荐被称为“冷启动问题”。
根据数据匮乏情况的不同,冷启动分为三类:
(1)用户冷启动,新用户注册后,没有历史行为数据时的个性化推荐。
(2)物品冷启动,系统加入新物品后(新的影片、新的商品等),在该商品还没有交互记录时,如何将该物品推荐给用户。
(3)系统冷启动,在推荐系统运行之初,缺乏所有相关历史数据时的推荐。
主流的冷启动策略归为以下三类:
(1)基于规则的冷启动过程。
(2)丰富冷启动过程中可获得的用户和物品特征。
(3)利用主动学习、迁移学习和“探索与利用”机制。
5.6.1 基于规则的冷启动过程(规则推荐)#
在冷启动过程中,由于缺乏数据,个性化推荐引擎无法有效工作,可以让系统回退到“前推荐系统”时代,采用基于规则的推荐方法。例如,在用户冷启动场景下,使用“热门排行榜”“最近流行趋势”“最高评分”等榜单作为默认的推荐列表。大多数音乐、视频等应用都是采用这类方法作为冷启动的默认规则。
更进一步,可以参考专家意见建立一些个性化物品列表,根据用户有限的信息,例如注册时填写的年龄、性别、基于 IP 推断出的地址等信息做粗粒度的规则推荐。例如,利用点击率等目标构建一个用户属性的决策树,在每个决策树的叶节点建立冷启动榜单,在新用户完成注册后,根据用户有限的注册信息,寻找决策树上对应的叶节点榜单,完成用户冷启动过程。
假设使用年龄和性别作为决策树的分裂条件,可以得到如下的决策树:
graph TD
A[年龄] -->|小于18岁| B[性别]
A -->|大于等于18岁| C[性别]
B -->|男| D[推荐列表: 《复仇者联盟4》、《星球大战9》、《蜘蛛侠:英雄远征》]
B -->|女| E[推荐列表: 《小妇人》、《冰雪奇缘2》、《狮子王》]
C -->|男| F[推荐列表: 《教父》、《肖申克的救赎》、《盗梦空间》]
C -->|女| G[推荐列表: 《泰坦尼克号》、《乱世佳人》、《当幸福来敲门》]
在物品冷启动场景下,可以根据一些规则找到该物品的相似物品,利用相似物品的推荐逻辑完成物品的冷启动过程。
本节以 Airbnb 为例说明该过程。
Airbnb 是全球最大的短租房中介平台。在新上线短租房时,Airbnb 会根据该房屋的属性对该短租房指定一个“聚类”,位于同样“聚类” 中的房屋会有类似的推荐规则。为冷启动短租房指定“聚类” 所依靠的规则有如下三条:
(1)同样的价格范围。
(2)相似的房屋属性(面积、房间数等)。
(3)距目标房源的距离在 10 公里以内。
找到最符合上述规则的 3 个相似短租房,根据这 3 个已有短租房的聚类定位冷启动短租房的聚类。
通过 Airbnb 的例子可以知道,基于规则的冷启动方法更多依赖的是领域专家对业务的洞察。在制定冷启动规则时,需要充分了解公司的业务特点,充分利用已有数据,才能让冷启动规则合理且高效。
5.6.2 丰富冷启动过程中可获得的用户和物品特征(特征工程)#
基于规则的冷启动过程在大多数情况下是有效的,但该过程与推荐系统的“主模型”是割裂的。还可以通过改进推荐模型达到冷启动,主要方法就是在模型中加入更多用户或物品的属性特征,而非历史数据特征。
在历史数据特征缺失的情况下,推荐系统仍然可以凭借用户和物品的属性特征完成较粗粒度的推荐。这类属性特征主要包括以下几类:
(1)用户的注册信息。包括基本的人口属性信息(年龄、性别、学历、职业等)和通过 IP 地址、GPS 信息等推断出的地理信息。
(2)第三方 DMP(Data Management Platform,数据管理平台)提供的用户信息,可以极大地丰富用户的属性特征。这些第三方数据管理平台不仅可以提供基本的人口属性特征,通过与大量应用、网站的数据交换,甚至可以提供脱敏的用户兴趣、收入水平、广告倾向等一系列的高阶特征。
(3)物品的内容特征。在推荐系统中引入物品的内容相关特征是有效地解决“物品冷启动”的方法。物品的内容特征可以包括物品的分类、标签、描述文字等。具体到不同的业务领域,还可以有更丰富的领域相关内容特征。例如,在视频推荐领域,视频的内容特征可包括,该视频的演员、年代、风格,等等。
(4)引导用户输入的冷启动特征。有些应用会在用户第一次登录时引导用户输入一些冷启动特征。例如,一些音乐类应用会引导用户选择“音乐风格”;一些视频类应用会引导用户选择几部喜欢的电影。这些都是通过引导页面来完成丰富冷启动特征的工作。
5.6.3 利用主动学习、迁移学习和“探索与利用”机制#
- 主动学习
主动学习是相比“被动学习”而言的。被动学习是在已有的数据集上建模,学习过程中不对数据集进行更改,也不会加入新的数据,学习的过程是“被动的”。而主动学习不仅利用已有的数据集进行建模,而且可以“主动”发现哪些数据是最急需的,主动向外界发出询问,获得反馈,从而加速整个学习的过程,生成更全面的模型。
主动学习模型是如何在推荐系统冷启动过程中发挥作用的呢?这里举一个实例加以说明。如图 5-16 所示,横轴和纵轴分别代表两个特征维度,图中的点代表一个物品(这里以视频推荐中的影片为例),点的深浅代表用户对该影片实际打分的高低。那么,图 5-16 就代表了一个冷启动的场景,即用户没对任何影片进行打分,系统应该如何进行推荐呢?
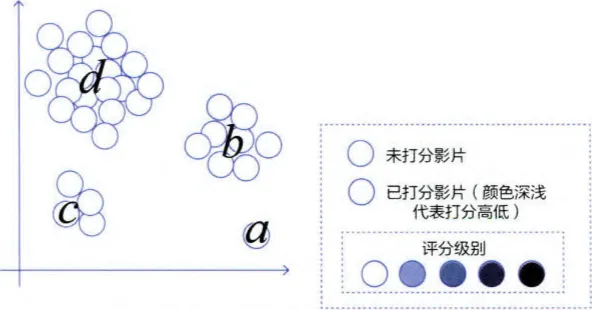
主动学习的学习目标是尽可能快速地定位所有物品可能的打分。可以看到,所有影片聚成了a、b、c、d 4类,聚类的大小不一。那么,以主动学习的思路,应该在下一次的推荐中选择哪部影片呢?
答案是应该选择最大聚类 d 的中心节点作为推荐影片,因为通过主动问询用户对 d 中心节点的打分,可以得到用户对最大聚类 d 的反馈,使推荐系统的收益最大。严格地讲,应定义推荐系统的损失函数,从而精确地评估推荐不同影片获得的损失下降收益。
主动学习的原理与强化学习一脉相承,回顾 3.10 节的强化学习框架不难发现,主动学习的过程完全遵循“行动-反馈-状态更新”的强化学习循环。它的学习目的就是在一次又一次的循环迭代中,让推荐系统尽量快速地度过冷启动状态,为用户提供更个性化的推荐结果。
- 迁移学习
迁移学习是在某领域知识不足的情况下,迁移其他领域的数据或知识,用于本领域的学习。那么,迁移学习解决冷启动问题的原理就不难理解了,冷启动问题本质上是某领域的数据或知识不足导致的,如果能够将其他领域的知识用于当前领域的推荐,那么冷启动问题自然迎刃而解。
迁移学习的思路在推荐系统领域非常常见。在 5.4 节介绍的 ESMM 模型中,阿里巴巴利用 CTR 数据生成了用户和物品的 Embedding,然后共享给 CVR 模型,这本身就是迁移学习的思路。这就使得 CVR 模型在没有转化数据时能够用 CTR 模型的“知识”完成冷启动过程。
其他比较实用的迁移学习的方法是在领域 A 和领域 B 的模型结构和特征工程相同的前提下,若领域 A 的模型已经得到充分的训练,则可以直接将领域 A 模型的参数作为领域 B 模型参数的初始值。随着领域 B 数据的不断积累,增量更新模型 B。这样做的目的是在领域 B 数据不足的情况下,也能获得个性化的、较合理的初始推荐。该方法的局限性是要求领域 A 和领域 B 所用的特征必须基本一致。
3.“探索与利用”机制
“探索与利用”机制是解决冷启动问题的另一个有效思路。探索与利用是在“探索新数据”和“利用旧数据”之间进行平衡,使系统既能利用旧数据进行推荐,达到推荐系统的商业目标,又能高效地探索冷启动的物品是否是“优质”物品,使冷启动物品获得曝光的倾向,快速收集冷启动数据。
这里以最经典的探索与利用方法 UCB(Upper Confidence Bound,置信区间上界)讲解探索与利用的原理。
以下是用 UCB 方法计算每个物品的得分的公式。其中 xj 为观测到的第 j 个物品的平均回报(这里的平均回报可以是点击率、转化率、播放率等),nj 为目前为止向用户曝光第 j 个物品的次数,n 为到目前为止曝光所有物品的次数之和。
通过简单计算可知,当物品的平均回报高时,UCB 的得分会高;同时,当物品的曝光次数低时,UCB 的得分也会高。也就是说,使用 UCB 方法,推荐系统会倾向于推荐“效果好”或者“冷启动”的物品。随着冷启动的物品有倾向性地被推荐,冷启动物品快速收集反馈数据,使之能够快速通过冷启动阶段。
“探索与利用”除了解决冷启动问题,还可以更好地挖掘用户潜在兴趣,维持系统的长期受益状态,5.7 节将着重探讨解决“探索与利用”问题的主流方法。
5.6.4 “巧妇难为无米之炊”的困境#
冷启动问题的难点在于没有米,还要让“巧妇”(算法工程师)做一顿饭。解决这个困局的两种思路:
(1)虽然没有米,但不可能什么吃的都没有,先弄点粗粮尽可能做出点吃的再说。这就要求冷启动算法在没有精确的历史行为数据的情况下,利用一些粗粒度的特征、属性,甚至其他领域的知识进行冷启动推荐。
(2)边做吃的边买米,快速度过“无米”的阶段。这种解决问题的思路是先做出点吃的,卖了吃的换钱买米,将饭越做越好,米越换越多。这就是利用主动学习、“探索与利用”机制,甚至强化学习模型解决冷启动问题的思路。
在实际的工作中,这两种方式往往会结合使用。
5.7 探索与利用#
一味使用历史数据,根据用户历史进行推荐,不注重发掘用户新的兴趣、新的优质物品,就会涸泽而渔。推荐系统应主动试探用户新的兴趣点,主动推荐新的物品,发掘有潜力的优质物品。
给用户推荐的机会是有限的,推荐用户喜欢的内容和探索用户的新兴趣都会占用宝贵的推荐机会,在推荐系统中应该如何权衡这两件事呢?这就是“探索与利用”试图解决的问题。
解决“探索与利用”问题目前主要有三大类方法。
(1)传统的探索与利用方法:将问题简化成多臂老虎机问题。主要算法有 ε-Greedy(ε 贪婪)、Thompson Sampling(汤普森采样)和 UCB。该类解决方法着重解决新物品的探索和利用,方法中并不考虑用户、上下文等因素,因此是非个性化的探索与利用方法。
(2)个性化的探索与利用方法:结合个性化推荐特点和探索与利用的思想,在考虑用户、上下文等因素的基础上权衡探索与利用。
(3)基于模型的探索与利用方法:将探索与利用思想融入推荐模型。
第7章 推荐系统的评估#
7.4 A/B测试与线上评估指标#
7.4.1 什么是A/B测试#
A/B 测试又称为“分流测试”或“分桶测试”,是一个随机实验,通常被分为实验组和对照组。在利用控制变量法保持单一变量的前提下,将 A、B 两组数据进行对比,得出实验结论。具体到互联网场景下的算法测试中,可将用户随机分成实验组和对照组,对实验组的用户施以新模型,对对照组的用户施以旧模型,比较实验组和对照组在各线上评估指标上的差异。
7.4.2 A/B测试的“分桶”原则#
在 A/B 测试分桶的过程中,需要注意的是样本的独立性和采样方式的无偏性:同一个用户在测试的全程只能被分到同一个桶中,在分桶过程中所用的用户 ID 应是一个随机数,这样才能保证桶中的样本是无偏的。
在实际的 A/B 测试场景中,同一个网站或应用往往要同时进行多组不同类型的 A/B 测试,例如在前端进行不同 App 界面的 A/B 测试,在业务层进行不同中间件效率的 A/B 测试,在算法层同时进行推荐场景 1 和推荐场景 2 的 A/B 测试。如果不制定有效的 A/B 测试原则,则不同层的测试之间势必互相干扰,甚至同层测试也可能因分流策略不当导致指标的失真。
7.5 快速线上评估方法——Interleaving#
对于诸多强算法驱动的互联网应用来说,为了不断迭代、优化推荐模型,需要进行大量 A/B 测试来验证新算法的效果。但线上 A/B 测试必然要占用宝贵的线上流量资源,还有可能对用户体验造成损害,这就带来了一个矛盾——算法工程师日益增长的 A/B 测试需求和线上 A/B 测试资源严重不足之间的矛盾。
针对上述问题,一种快速线上评估方法——Interleaving 于 2013 年被微软正式提出,并被 Netflix 等公司成功应用在工程领域。具体地讲,Interleaving 方法被当作线上 A/B 测试的预选阶段(如图 7-7 所示)进行候选算法的快速筛选,从大量初始想法中筛选出少量“优秀”的推荐算法。再对缩小的算法集合进行传统的 A/B 测试,以测量它们对用户行为的长期影响。
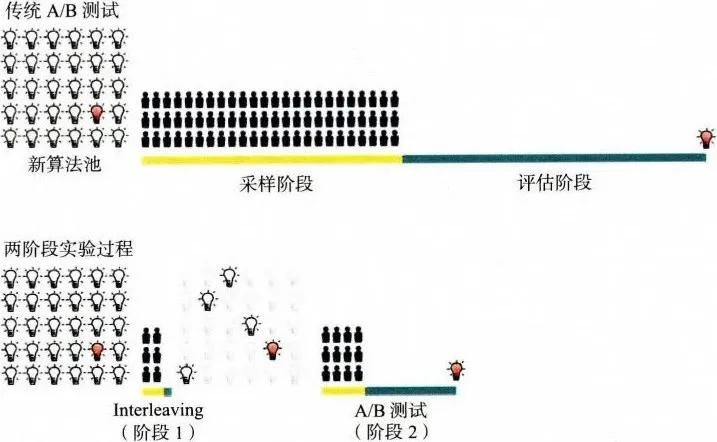
图 7-7 中用灯泡代表候选算法。其中,最优的获胜算法用红色灯泡表示。Interleaving 能够快速地将最初的候选算法集合进行缩减,比传统的 A/B 测试更快地确定最优算法。笔者将以 Netflix 的应用场景为例,介绍 Interleaving 方法的原理和特点。
7.5.1 传统A/B测试存在的统计学问题#
传统的 A/B 测试除了存在效率问题,还存在一些统计学上的显著性差异问题。下面用一个很典型的 A/B 测试例子进行说明。
设计一个 A/B 测试来验证用户群体是否对“可口可乐”和“百事可乐”存在口味倾向。按照传统的做法,会将测试人群随机分成两组,然后进行“盲测”,即在不告知可乐品牌的情况下进行测试。第一组只提供可口可乐,第二组只提供百事可乐,然后根据一定时间内的可乐消耗量观察人们是更喜欢“可口可乐”还是“百事可乐”。
这个实验在一般意义上确实是有效的,但也存在一些潜在的问题:
在总的测试人群中,对于可乐的消费习惯肯定各不相同,从几乎不喝可乐到每天喝大量可乐的人都有。可乐的重消费人群肯定只占总测试人群的一小部分,但他们可能占整体汽水消费的较大比例。
这个问题导致 A/B 两组之间重度可乐消费者的微小不平衡,也可能对结论产生不成比例的影响。
在互联网应用中,这样的问题同样存在。在 Netflix 的场景下,非常活跃用户的数量是少数,但其贡献的观看时长却占较大的比例,因此,在 Netflix 的 A/B 测试中,活跃用户被分在 A 组的多还是被分在 B 组的多,将对测试结果产生较大影响,从而掩盖了模型的真实效果。
如何解决这个问题呢?一个可行的方法是不对测试人群进行分组,而是让所有测试者都可以自由选择百事可乐和可口可乐(测试过程中仍没有品牌标签,但能区分是两种不同的可乐)。在实验结束时,统计每个人消费可口可乐和百事可乐的比例,然后对每个人的消费比例进行平均,得到整体的消费比例。
这个测试方案的优点在于:
(1)消除了 A/B 组测试者自身属性分布不均的问题。
(2)通过给予每个人相同的权重,降低了重度消费者对结果的过多影响。
这种不区分 A/B 组,而是把不同的被测对象同时提供给受试者,最后根据受试者喜好得出评估结果的方法就是 Interleaving 方法。
7.5.2 Interleaving方法的实现#
图 7-8 描绘了传统 A/B 测试和 Interleaving 方法之间的差异。
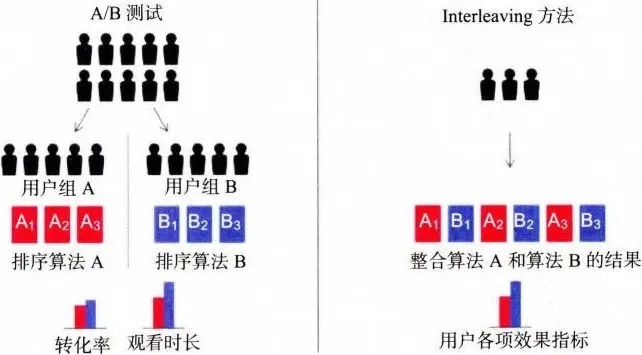
在传统的 A/B 测试中,Netflix 会选择两组订阅用户:一组接受排序算法 A 的推荐结果,另一组接受排序算法 B 的推荐结果。
而在 Interleaving 方法中,只有一组订阅用户,这些订阅用户会收到通过混合算法 A 和 B 的排名生成的交替排名。
这就使得用户可以在一行里同时看到算法 A 和 B 的推荐结果(用户无法区分一个物品是由算法 A 推荐的还是由算法 B 推荐的),进而通过计算观看时长等指标来衡量到底是算法 A 的效果好还是算法 B 的效果好。
当然,在使用 Interleaving 方法进行测试的时候,必须考虑位置偏差的存在,避免来自算法 A 的视频总排在第一位。因此,需要以相等的概率让算法 A 和算法 B 交替领先。这类似于在野球场打球时,两个队长先通过扔硬币的方式决定谁先选人,再交替选队员的过程。
7.5.3 Interleaving方法与传统A/B测试的灵敏度比较#
Interleaving 方法利用 个样本就能判定算法 A 是否比 B 好,而 A/B 测试则需要 个样本才能将 p-value 降到 5% 以下,即使与最敏感的 A/B 测试指标相比,Interleaving 也只需要 1% 的订阅用户样本就能够确定用户更偏爱哪个算法。这就意味着利用一组 A/B 测试的资源,可以做 100 组 Interleaving 实验,这无疑极大地加强了线上测试的能力。
7.5.5 Interleaving方法的优点与缺点#
Interleaving 方法也存在一定的局限性,主要表现在以下两方面。
(1)工程实现的框架较传统 A/B 测试复杂。Interleaving 方法的实验逻辑和业务逻辑纠缠在一起,因此业务逻辑可能会被干扰。为了实现 Interleaving 方法,需要将大量辅助性的数据标识添加到整个数据流中,这都是工程实现的难点。
(2)Interleaving 方法只是对“用户对算法推荐结果偏好程度”的相对测量,不能得出一个算法真实的表现。如果希望知道算法 A 能够将用户整体的观看时长提高了多少,将用户的留存率提高了多少,那么使用 Interleaving 方法是无法得出结论的。为此,Netflix 设计了 Interleaving+A/B 测试两阶实验结构,完善整个线上测试的框架。
第8章 深度学习推荐系统的前沿实践#
8.3 YouTube深度学习视频推荐系统#
8.3.5 排序模型#
通过候选集生成模型,得到几百个候选视频集合,然后利用排序模型进行精排序,YouTube 推荐系统的排序模型如图 5-9 所示。
第一眼看上去,读者可能会认为排序模型的网络结构与候选集生成模型没有太大区别,在模型结构上确实是这样的,这里需要重点关注模型的输入层和输出层,即排序模型的特征工程和优化目标。
相比候选集生成模型需要对几百万候选集进行粗筛,排序模型只需对几百个候选视频进行排序,因此可以引入更多特征进行精排。具体地讲,输入层从左至右的特征依次是:
(1)当前候选视频的 Embedding(impression video ID embedding)。
(2)用户观看过的最后 N 个视频 Embedding 的平均值(watched video IDs average embedding)。
(3)用户语言的 Embedding 和当前候选视频语言的 Embedding(language embedding)。
(4)该用户自上次观看同频道视频的时间(time since last watch)。
(5)该视频已经被曝光给该用户的次数(#previous impressions)。
上面 5 个特征中,前 3 个的含义是直观的,这里重点介绍第 4 个和第 5 个特征。因为这两个特征很好地引入了 YouTube 对用户行为的观察。
第 4 个特征 time since last watch 表达的是用户观看同类视频的间隔时间。从用户的角度出发,假如某用户刚看过“DOTA 比赛经典回顾”这个频道的视频,那么用户大概率会继续看这个频道的视频,该特征很好地捕捉到了这一用户行为。
第 5 个特征#previous impressions 则在一定程度上引入了 5.7 节介绍的“探索与利用”机制,避免同一个视频对同一用户的持续无效曝光,尽量增加用户看到新视频的可能性。
需要注意的是,排序模型不仅针对第 4 个和第 5 个特征引入了原特征值,还进行了平方和开方的处理。作为新的特征输入模型,这一操作引入了特征的非线性,提升了模型对特征的表达能力。
8.4 阿里巴巴深度学习推荐系统的进化#
8.4.1 推荐系统应用场景#
阿里巴巴的应用场景读者可能比较熟悉,无论是天猫还是淘宝,阿里巴巴推荐系统的主要功能是根据用户的历史行为、输入的搜索词及其他商品和用户信息,在网站或 App 的不同推荐位置为用户推荐感兴趣的商品。
在解决推荐问题时,熟悉场景中的细节要素和用户操作的不同阶段是重要的。例如,某用户希望在天猫中购买一个“无线鼠标”,从登录天猫到购买成功,一般需要经历以下几个阶段(图 8-17 展示了用户搜索“无线鼠标”时的推荐结果)。
图 8-17 在天猫中搜索“无线鼠标”时的推荐结果
(1)登录。
(2)搜索。
(3)浏览。
(4)点击。
(5)加入购物车。
(6)支付。
(7)购买成功。
每一步都存在着用户的流失,又以“浏览-点击”,“点击-加入购物车”最为关键。那么,到底应该为这两个阶段的行为单独建立 CTR 模型和 CVR 模型,还是统一建模呢?5.4 节介绍的多目标优化模型 ESMM 给出了阿里巴巴技术人员对这个问题的思考。
8.4.2 阿里巴巴的推荐模型体系#
阿里巴巴推荐模型进化过程的重点在于对用户历史行为的利用。一方面,用户历史行为确实在推荐中扮演着至关重要的作用;另一方面,得益于阿里巴巴极高的数据质量,其在电商领域的领先地位决定了它的数据能够保存大部分用户的购买兴趣特征,从而有效地对其建模。图 8-20 所示为某女性用户的购买历史。这个例子(每个图片代表该用户购买过的一个商品)很好地解释了阿里巴巴不同推荐模型对用户行为的建模原理。
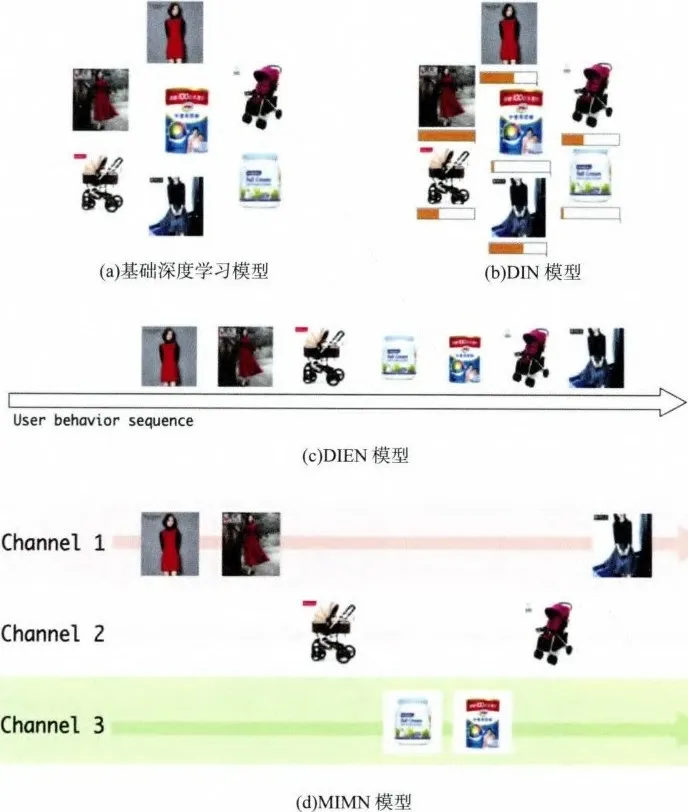
图 8-20(a)是基础深度学习模型对待用户行为的办法,即一视同仁,不分重点;从图 8-20(b)中可以看出,每个商品开始有了一个用进度条表示的权重,这个权重是基于该商品与候选商品的关系,通过注意力机制学习出来的。这就让模型具备了有重点地看待不同用户行为的能力;图 8-20(c)中的用户行为有了时间维度,行为历史按照时间轴被排列成了一个序列,DIEN 模型开始考虑用户行为和用户兴趣随时间变化的趋势,这让模型真正具备了下次购买的预测能力;图 8-20(d)中的用户行为不仅被排成了序列,而且根据商品种类的不同被排列成了多个序列,这使得 MIMN 模型开始对用户多个“兴趣通道”进行建模,更精准地把握用户的兴趣变迁过程,避免不同兴趣之间相互干扰。